https://arxiv.org/pdf/1511.06939.pdf
Abstract
이 논문에서는 RNN model을 Recsys 분야에 새롭게 대입하려 하였다.
당시 사용되던 recsys는 Netflix와 같이 long session-based data보다는 일반적인 사이트에서 얻어온 short session-based data에 의존한다는 문제에 직면한다.
이러한 상황에서는 MF 방법이 효과적으로 적용될 수 없기에, item간의 추천에 의존함으로써 해당 문제를 극복할 수 있다고 한다.
전체 session을 modeling 하면 더욱 정확한 추천을 할 수 있다.
따라서 저자는 RNN-based approach를 제시하였고, ranking loss나 다른 몇몇의 부분들을 수정한 새로운 RNN 모델을 제시하였다.
Introduction
Session-based 추천시스템은 머신러닝 분야에서 많이 사용되지 않던 분야이다.
대부분의 e-commerce나 news, media 사이트들은 오랜 시간동안 user의 id를 추적하지 않는다.
이는 privacy 문제를 야기할 수 있고, 충분하게 reliable하지도 않다.
추적이 가능하더라도 대부분의 user는 한두개의 세션만을 가지고 있고, 어떤 domain에서는 user의 행동이 session-based 특성을 보이기도 한다.
따라서 같은 사용자의 후속 session은 독립적으로 다루어져야한다.
결과적으로 대부분의 session-based recommendation system은 (특히 전자상거래 domain에서) 아이템간의 유사성이나 co-occurrence와 같이 사용자의 정보를 사용하지 않는 비교적 간단한 방법으로 진행된다.
이러한 방법은 효과적이긴 하지만, 종종 사용자의 마지막 클릭이나 선택만을 고려하기 때문에 과거의 클릭정보를 무시해버리기도 한다.
추천시스템에서 자주 사용하는 방법은 Factor model인데 session-based에서는 user 정보가 없기 때문에 적용하기 힘들다.
반대로 neighborhood 방법은 item 사이의 co-occurrences를 이용하기 때문에 세션 기반 추천시스템에 적합하다.
이 연구에서는 RNN이 추천시스템에 적용되어 주목할만한 성과를 내었다고 주장한다.
세션 기반 추천에서의 문제점은 NLP와 관련된 문제점과 일부 유사한 점이 존재하는데, 둘 다 sequence를 modeling 하고 있기 때문이다.
세션 기반 추천에서 저자는 웹사이트에 들어가기 위한 첫번째 클릭을 RNN의 initial input으로 생각하였고,
사용자의 연속적인 클릭이 input으로 들어온 경우 이전 클릭에 기반해 recommendation output을 만들어낸다.
일반적으로 추천시스템에서의 item 집합의 개수는 만에서 십만정도의 크기를 가지고,
item set의 큰 크기와는 별개로 click-stream dataset이 상당히 크기 때문에 training time과 scalability가 매우 중요하다
Customizing the GRU model
Input 은 session의 actual state이고 output은 session의 그 다음 event의 item이다.
session의 state는 actual event의 item을 의미하거나 그때까지의 session event를 의미한다.
전자의 경우 1-of-N encoding이 사용되는데, input vector의 길이는 항상 item의 개수로 같고 단지 해당하는 active item은 하나이기 때문이다. (나머지는 없음)
후가의 경우 해당 representation들의 weighted sum이 사용되는데 event가 더 빨리 일어날수록 discount된다.
input vector는 안정성을 위해 normalized된다.
저자는 추가적인 embedding layer를 덧붙여서 실험을 진행하였지만 1-of-N encoding이 항상 좋은 성능을 냈다고 한다.
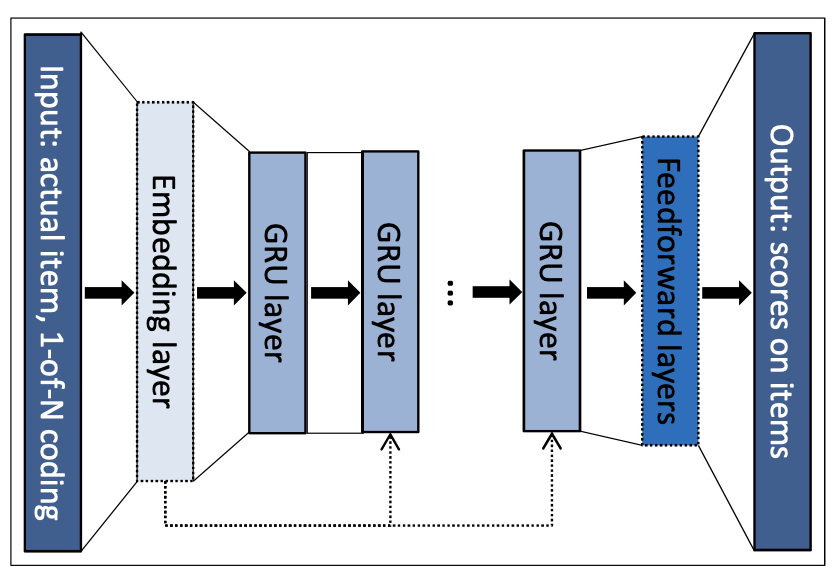
위 network의 가장 핵심은 GRU layer이고 추가적인 feedforward layer는 가장 마지막 GRU layer와 output layer 사이에 추가될 수 있다.
output은 item의 예측된 선호도를 나타낸다. 즉, 각각의 item에 대해 현재 session에서 다음에도 존재할 선호도를 의미한다.
만약 여러개의 GRU layer가 사용된다면, 이전 layer의 hidden state가 다음 layer의 input으로 들어가게 되고, 더욱 layer가 깊어질수록 성능이 좋아진다는 것을 확인하였다.
RNN이 추천시스템에 최적화된 모델이 아니기 때문에 저자는 task에 맞추기 위해 모델을 수정하였다.
Session-parallel mini-batches
기존에 사용하던 sliding window를 단어들에 적용시켜가며 학습을 진행하는 것은 이번에 진행할 task와는 잘 맞지 않는데
1) session의 길이가 서로 다르다.
2) 이 task의 목표가 시간이 지남에 따라 어떻게 session이 진행되어 가는지를 확인하는 것이기 때문에, 부분으로 쪼개는 것은 말이 되지 않는다
따라서 저자는 session-parallel mini-batches를 아래와 같이 사용하게 되었다.

첫번째로, session의 순서를 만든다.
첫번째 mini-batch의 input을 만들기 위해 처음 X session의 첫번째 event를 사용한다.
두번째 mini-batch는 두번째 event로부터 만들어지고, 다음도 이와 같다.
만약 어떤 session이 끝나게 된다면 다음 available한 session이 그 자리를 이어받는다.
각각의 Session은 서로 독립적이라고 가정하기 때문에 만약 switch가 발생하면 hidden state를 적절히 reset 시켜주어야 한다.
Sampling on the output
추천시스템에서는 아이템의 개수가 매우 많고, item에 대한 score를 계산할 때 inner product로 계산하여야 하기 때문에 이는 현실에서는 거의 사용할 수 없는 방법이다. 그러므로 item의 subset를 추출하여 score를 계산하여야 한다.
게다가 원하는 결과를 위해서 저자는 negative examples에서도 score를 계산할 필요가 있다고 보고, weight를 수정해서 바람직한 결과가 높게 rank될 수 있도록 하였다.
missing event에 대한 보통의 해석은 user가 해당 item의 존재를 몰라 interaction이 없다고 보는 것이다.
하지만 여기엔 아주 낮은 확률로 사용자가 아이템의 존재를 알았고, 그 아이템을 싫어했기 때문에 interaction하지 않기로 선택할 수 있는 경우의 수가 존재한다.
아이템이 더욱 인기가 많을수록 사용자는 그 아이템을 알고 있을 확률이 크고, 이런데도 상호작용이 없었다면 사용자가 싫어하는 아이템이라고 생각하도록 설계하였다.
따라서 각각의 training example에서 sample들을 만들어내는 것보단 negative example을 이용해 새로운 training example로부터 item을 이용하도록 한다.
이러한 방법의 장점은 sampling 과정을 skip하면서 계산 과정에 들어가는 시간을 크게 줄일 수 있고, 코드로 구현할 때도 훨씬 간편하다는 것이다.
Ranking Loss
추천시스템의 핵심은 아이템들의 relevance-based ranking이라는 것이다.
Ranking은 point-wise, pair-wise, list-wise가 있다.
- point-wise ranking은 아이템의 score와 rank를 각각마다 구하는 방법이다.
- pair-wise ranknig은 positive - negative item pair의 score와 rank를 비교하고, Loss는 positive item의 rank가 negative item보다 더 낮도록 구현한다.
- list-wise ranking은 모든 item의 score와 rank를 사용하고, perfect ordering을 통해 비교한다.
이 방법이 sorting을 해야하기 때문에 computationally more expensive하고, 자주 사용하지 않는다.
이 모델에서는 point-wise ranking 방법이 불안정하기 때문에 여기서는 BPR, TOP1과 같은 pairwise ranking을 사용하였다.
Conclusion
이 논문에서는 RNN 계열의 GRU를 추천시스템이라는 새로운 application에 접목시키려 하였다.
특히 session-based recommendation에 적용시키려 하였는데, 이는 이 분야가 매우 중요한 area이지만 많이 연구가 되지 않았기 때문이다.
여기서 제안한 모델은 놀라운 outperformance를 보여주었다.




댓글