https://arxiv.org/pdf/1808.09781.pdf
Abstract
최근 추천시스템에선 사용자의 activities에 대한 context를 포착하는 것이 key feature가 되었다.
이러한 패턴을 얻기 위해 Markv Chain과 RNN이 사용되고 있는데,
MC의 경우 이전 action들을 이용하여 사용자의 다음 action을 예측하는 방법으로 극단적으로 sparse dataset에 좋은 성능을 보이지만 그렇기 때문에 model의 parsimony가 critical하고,
RNN의 경우 longer-term semantics를 얻도록 하는 방법으로 denser dataset에서 좋은 성능을 보이지만 그만큼 더욱 높은 model complexity가 필요하다.
이 논문에서의 목표는 위 언급한 두가지의 특성을 잘 조화시키는 것이다.
self-attention based sequential model(SASRec)을 제안하여 long-term semantics들을 포착함(Like RNN)과 동시에 적은 action만으로도 예측을 진행(Like MC)할 수 있도록 하였다.
각 step마다 SASRec은 사용자의 action history에서 아이템의 relevant를 찾고, 다음 아이템을 예측하기 위해 사용한다.
실험을 진행해보았을 때, model이 sparse, dense dataset 모두 SOTA의 성능을 내는 것을 확인하였다.
Introduction
Sequencial 추천시스템은 사용자의 최근 action에 기반한 맥락을 이용하여 다음 행동을 예측한다.
유용한 패턴을 sequential dynamics에서 찾아내는 것이 중요한데, 맥락에서 찾아낼 수 있는 이전의 action들이 기하급수적으로 증가하여 input space가 커지기 때문이다.
그래서 sequential 추천에서는 어떻게 많은 input 속에서 효과적인 정보를 포착할 수 있는지가 연구의 목적이 된다.
MC-based method에서는 간단하면서 높은 sparsity의 data를 이용할수록 좋은 성능을 보이지만, 더욱 복잡한 scenario에서의 성능은 떨어진다.
반대로 RNN에서는 좋은 성능을 내기위해 이전의 많은 양의 data를 필요로 하게 된다.
최근 새로운 sequential model인 Transformer가 MT task에서 새로운 SOTA를 내게 되었는데,
여기서 활용된 self-attention이 단어 사이의 syntactic, semantic pattern을 매우 효율적으로 찾아낸다는 것이 확인되었다.
저자는 self-attention 매커니즘을 활용하여 sequential 추천시스템에 적용시키려 하였고,
이 아이디어가 과거의 모든 action으로부터 context를 만들고(Like RNN), 다른 측면으로는 적은 수의 action 만으로 다음 예측을 진행할 수 있다는 점(like MC)을 기대하였다.
Methodology
sequential 추천에서 사용자의 action sequence가 주어지면, 이를 이용하여 다음 아이템을 예측한다.
training 과정에서 step t일 때, 모델은 이전 t개의 item을 이용하여 다음 item을 예측한다.
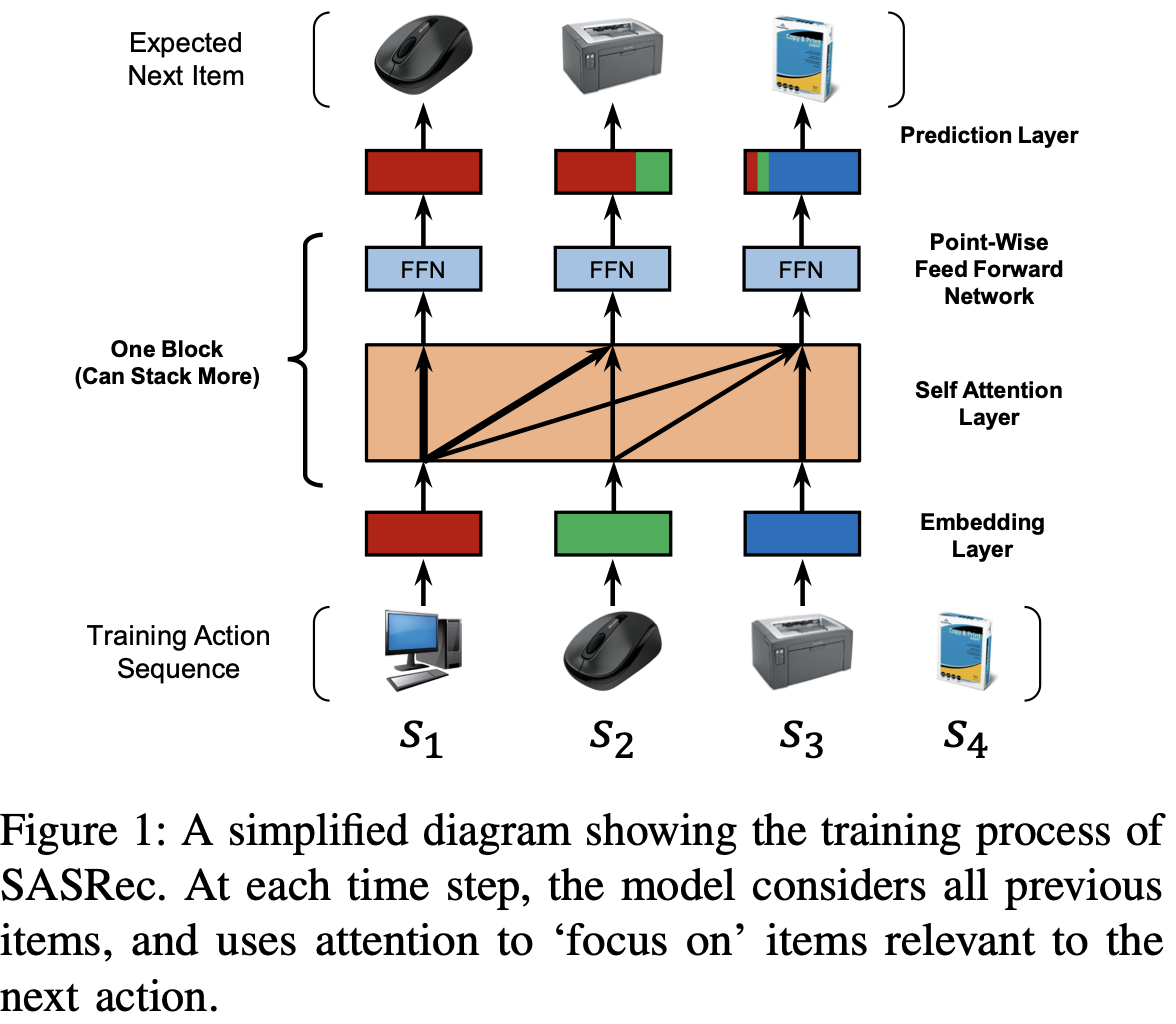
Fig 1을 보면 편한데,
S = {S1, S2, S3, ...}이 input으로 들어온 경우, 각각의 output은 input의 shift version인 {S2,S3,S4,...}가 되도록 training을 진행한다.
A. Embedding Layer
먼저 training sequence를 model이 다룰 수 있는 최대 길이 n으로 고정한 새로운 sequence로 변환한다.
만약 n보다 긴 길이의 sequence가 들어온 경우 가장 최근의 n action만 고려하도록 하고, n보다 짧은 길이의 sequence가 들어온 경우 길이가 n이 될때까지 padding item을 추가하여 길이를 맞춘다.
Positional Embedding
self-attention model은 RNN이나 CNN 부분이 없기 때문에, 이전 item의 위치를 인식하지 못한다.
따라서 trainable한 position embedding vector P 를 input embedding에 추가한다.
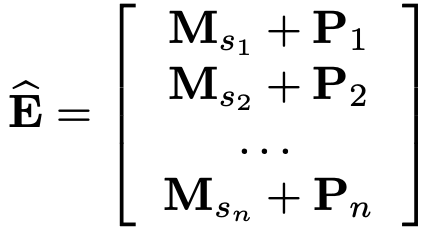
저자는 따로 fixed position embedding을 이용하여 실험을 진행해보았지만 trainable embedding보다 더 좋지 않은 성능을 보였다고 한다.
Self-Attention Block

이 논문에서의 self-attention operation는 embedding E^을 input으로 하고,
선형변환을 통해 3개의 matrices를 이용하여 attention으로 바꾼다.
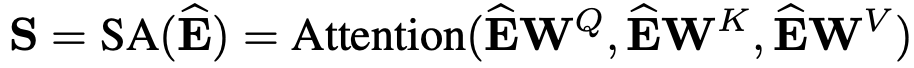
Projection Matrix W는 model을 flexible하게 만든다.
Casuality
sequence의 특성때문에 model이 t+1번째의 item을 예측할 때에는 그 전에 입력된 t개의 item만 사용하여야 한다.
하지만 self-attention layer 의 t번째 output은 subsequent item들의 embedding을 포함하고 있고, 이는 model의 ill-posed 현상을 발생시킨다.
따라서 t번째 이후의 모든 attention link를 제거하는 방법으로 모델을 수정하였다.
Point-Wise Feed-Forward Network
self-attention이 이전의 모든 item embedding을 결합할 수 있지만, 여전히 linear model이다.
서로 다른 latent dimension들 사이의 interaction을 고려하고, model에 non-linearity를 적용시키기 위해
모든 Si에 동일하게 point-wise two-layer feed-forward network를 적용한다.

Si와 Sj 사이에는 interaction이 없고, 이는 이 방법이 뒤에서 앞으로 오는 information leak 현상을 막을 수 있다는 것을 의미한다.
C. Stacking Self-attention Blocks
첫번째 self-attention block 이후에 FFN은 이전 모든 아이템의 embedding들을 결합한다.
여러개의 self-attention block을 쌓게 되면 아래와 같은 식으로 정리할 수 있다.
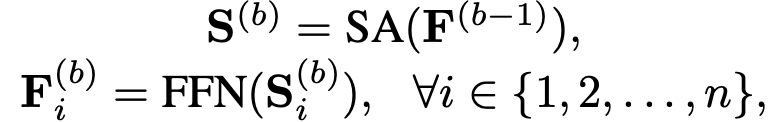
하지만 계속 쌓게되면 1) overfitting이 유도될 수 있음, 2) 훈련 과정이 불안정함(vanishing gradients 문제 발생), 3) 더욱 많은 parameter를 필요로 하기 때문에 훈련 시간이 커짐
위와 같은 문제점들을 완화하기 위해 operation을 다음과 같이 수정할 수 있다.
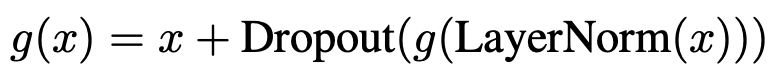
Residual connections
sequential 추천방법에서 가장 마지막으로 방문한 item이 다음 item을 예측하는데 가장 중요한 key가 된다.
하지만 몇번의 self-attention block을 거치고 나서는 마지막으로 방문한 item embedding이 이전의 다른 모든 item들에 의해 얽히게 된다.
따라서 residual connection을 추가해서 last visitied item의 embedding을 final layer에 전달하면서 model이 low-layer information으로부터 더욱 쉽게 예측할 수 있도록 할 수 있다.
D. Prediction Layer
b개의 self-attention block 이후, 저자는 처음 t개의 아이템이 주어졌을 때, 다음 아이템을 예측하기 위해서 MF layer를 채택하였다.

r_i,t : 처음 t개의 item이 주어진 경우 다음 아이템 i와의 relevance
N : item embedding matrix
따라서 높은 interaction score r_i,t는 높은 relevance를 의미하고, 저자는 추천을 score를 ranking 하면서 만들어낼 수 있다고 한다.
Conclusion
저자는 새로운 self-attention based sequential model인 SASRec을 제안하였다.
실험을 진행해보았을 때 sparse / dense dataset 모두 outperform을 보여주었고, 다른 CNN/RNN approaches보다 더 빠른 결과를 보여주었다.




댓글