https://arxiv.org/pdf/1904.06690.pdf
Abstract
유저의 historical 행동으로부터 dynamic 선호도를 모델링하는 것은 현재까지도 연구 중이고, 추천시스템 내에서도 중요한 역할을 한다.
이전 방법들은 sequential neural network를 이용하여 유저의 historical interaction들을 left-to-right하게 encode한다.
이 방법은 효과적이긴 하지만, left-to-right unidirectional 모델들은 다음과 같은 이유 때문에 sub-optimal하다.
a) 유저의 행동 시퀀스의 hidden representation의 power를 제한한다.
b) 순서가 정해져 있는 시퀀스는 항상 유용하지는 않다.
이러한 limitation을 다루기 위해, 저자는 유저의 행동 시퀀스를 모델링하기 위해 deep bidirectional self-attention를 차용한 BERT4Rec 모델을 제안하였다.
information leakage를 피하고, 효율적으로 bidirectional model을 train하기 위해, 저자는 Cloze objective를 채택하였고, left와 right context를 같이 사용하는 시퀀스 속에서 random masked item을 예측하도록 한다.
이 방법을 통해 저자는 user historical behavior 속에 있는 각각의 item들이 both left and right side로부터 information들이 혼합될 수 있도록 한다고 한다.
Introduction
여러 실제 세계의 application에서, 유저의 현재 interests는 과거 그들의 historical behavior들에 영향을 받아 dynamic 하고 evolving하다.
예를들어 일반적인 상황속에선 사용자가 consol accessories(e.g., Joy-Con controllers)를 구매하지 않을 수 있지만, 닌텐도 스위치를 구매하고 나서는 consol accessories를 구매할 수도 있다.
이러한 sequential dynamics를 modeling하기 위해, 사용자의 historical interaction에 기반한 sequential 추천시스템을 제안하였다.
이전 work들의 기본적인 패러다임은 left-to-right 시퀀셜 모델을 이용하여 사용자의 historical interaction을 encoding 하였다.
하지만 이러한 효과에도 불구하고, left-to-right unidirectional model은 사용자의 behavior sequence를 이용한 optimal representation을 학습하기에는 충분하지 않다고 주장하였다.
가장 큰 limitation은 historical sequence 속 item에 대한 hidden representation의 power를 제한한다는 것인데, 이는 오로지 이전 item에 대해서만 information을 encoding하기 때문에 발생한다.
또 다른 limitation으로는 이전 unidirectional model은 text나 time series data와 같은 natural order에 대해서 다룬다는 것인데, 실제 세계에서의 상황에서는 정해진 순서에 따른 데이터가 상항 true인 것은 아니라고 주장한다.
실제로 user's historical interaction 에서의 item 선택은 눈에 보이지 않는 외부적인 요인에 따라 순서를 따르지 않을 수 있음을 말한다.
이러한 상황속에서는 두가지 방향 모두를 고려한 context를 결합하는 것이 중요하다.
위 언급한 limitation을 다루기 위해, 사용자의 historical behavior sequence에 대한 representation을 학습하기 위해 저자는 bidirectional model인 BERT model을 사용할 것을 제안하였다.
BERT의 self-attention은 양방향의 context를 효과적으로 결합할 수 있고, rigid order assumption에 대해서도 저자의 model은 unidirectional model보다 더욱 suitable하다고 한다.
이는 bidirectional model에 있는 모든 아이템들이 left와 right side 모두로부터 context를 이용할 수 있기 때문이다.
기존 모델들은 left-to-right를 고려하여 학습을 진행하였기 때문에 양방향의 train는 straightforward나 intuitive하지 않다.
따라서 저자는 Cloze task를 사용하는데, random하게 일부 아이템들을 masking하고 해당 token을 복원하도록 train하는 방법을 채택하였다.
BERT4Rec
Problem Statement
| set of users | 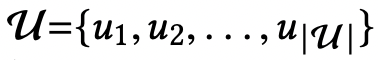 |
| set of items |  |
| interaction sequence list | 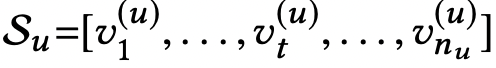 |
n_u : user u가 가지고 있는 interaction sequence의 길이
그리고 다음의 확률을 구하고자 한다.

Model Architecture

BERT4Rec은 L개의 bidirectional Transformer layer를 쌓아 만든다.
각각의 layer에서는 이전에 있는 layer에 있는 모든 position의 information들을 섞음으로써 모든 position들을 representation들을 수정한다.
Self-attention은 BERT4Rec에 어떠한 distance에 있는 dependencies들이더라도 직접적으로 capture할 수 있도록 한다.
CNN 계열의 'Caser'는 제한된 receptive field를 가지지만, 위 매커니즘을 가지게 되면 global receptive field를 가지게 된다.
Transformer Layer
Multi-Head Self-Attention
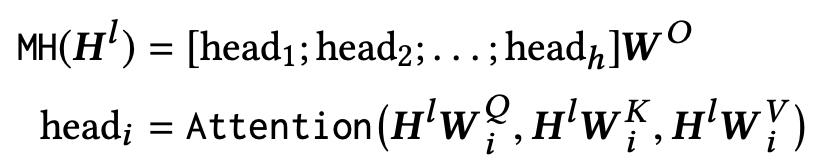
이 모델에서는 single attention function 대신 multi-head self-attention을 사용하였다.
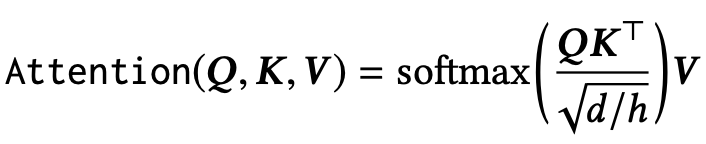
또한 gradient가 극단적으로 작아지는 것을 막기위해 scaled dot-product attention을 사용하였다.
Position-wise Feed-Forward Network
self-attention sub-layer는 위에서와 같이 내적을 통해 계산되기 때문에 linear projection이다.
모델에 non-linearity와 서로 다른 dimensions 사이에 interaction을 부여하기 위해, Position-wise Feed-Forward Network를 각각의 position마다 separately and identically하게 적용한다.
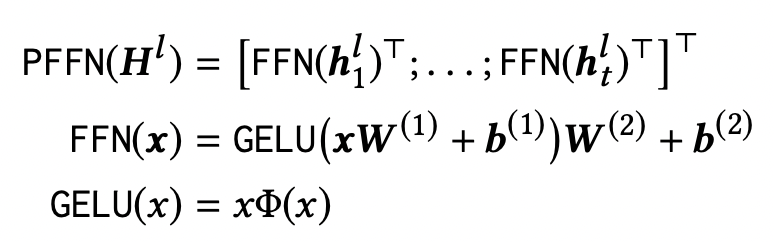
Stacking Transformer Layer
self-attention layer가 깊어지면 깊어질수록 성능이 좋아지긴 하지만, 정보들이 계속 섞이기 때문에 train이 더욱 어려워진다.
따라서 Layer normalization 위에 residual connection을 추가하였다.
LN의 경우 input들을 normalize 하여 network training의 stabilizing, accelerating 효과를 줄 수 있다.
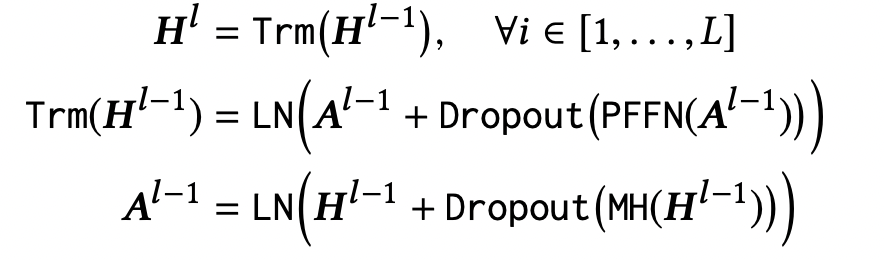
Embedding Layer
어떠한 recurrence나 convolution module 없이는 Transforemr layer Trm은 input sequence의 순서를 알지 못하기 때문에, Transformer layer stacks의 가장 아랫부분에서 Positional Embeddings를 input item embeddings에 추가한다.
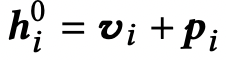
Output layer

HL : final output for all items of the input sequence
Wp: learnable projection matrix
b^p, b^O : bias term
time step t에서 masking된 item을 vt라고 하면, masked item vt를 h_t^L을 이용하여 예측하게 된다.
Model Learning
Train
양방향 모델을 사용하는 방법은 시간적, 자원적 소모가 굉장하다.
따라서 해당 모델을 더욱 효율적으로 train하기 위해, Cloze task를 시퀀셜 추천에 차용하였다.
매 training step마다 일정 비율만큼 input sequence에서 masking하고, masking 된 token들을 해당 token의 left, right context를 이용하여 복원하도록 훈련된다.
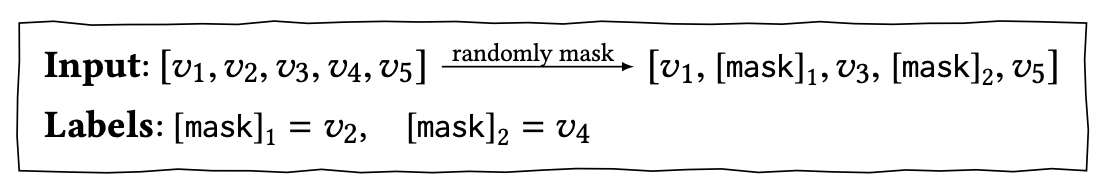
[mask]에 대응하는 final hidden vector는 output softmax에 들어가게 된다.
Loss function은 다음과 같다.

S'u : masked version for user behavior history Su
Su^m : random masked items in it
vm* : true item for the masked item 'vm'
Cloze 의 추가적인 이점으로는 model을 train하기 위한 sample들을 더욱 많이 만들어 낼 수 있다는 점이다.
이는 양방향 representation model을 훈련하는데 더욱 powerful하게 만들어 준다.
Test
이 방법은 training과 final sequential recommendation 사이에 mismatch를 발생시킬 수 있는데, 이는 Cloze objective가 현재의 masked item을 예측하도록 훈련되는 반면, sequential recommendation은 future를 예측하는데 중점을 두고 있기 때문이다.
이러한 문제점을 다루기 위해, user's behavior sequence의 끝에 "[mask]"라는 special token을 추가하여 이 token의 final hidden representation을 이용해 다음 item을 예측한다.
Conclusion
Deep bidirectional self-attention architecture는 language understanding 분야에서 엄청난 성공을 거두었다.
이 논문에서 저자는 Deep bidirectional sequential model인 BERT4Rec을 제안하였고, Cloze task를 적용하여 다음 item을 예측할 때 양방향의 context 모두 사용하도록 하였다.
real-world dataset에 대한 experimental result를 살펴보면 해당 모델이 SOTA의 성능을 낸다는 것을 확인할 수 있었다.




댓글