https://arxiv.org/pdf/2005.11401.pdf
0. Abstract
Large pre-trained language model은 model의 parameter에 factual knowledge를 저장하여 여러 downstream NLP task에 SOTA의 성능을 내고 있다.
하지만 여전히 access하고 정확하게 knowledge를 manipulate하는 능력은 제한적이다.
또한 해당 모델의 결정에 대한 근거를 제공하는 것과 그들은 world knowledge를 updating하는 것은 여전히 문제로 남아있다.
저자는 general-purpose fine-tuning recipe for retireval augmented generation(RAG) 모델을 제안하였고,
pre-trained parametic memory와 non-parametic memory를 결합하였다.
parametic memory는 pretrained seq2seq 모델을 이용하였고,
non-parametic memory는 pre-trained neural retriever로 access된 Wikipedia의 dense vector이다.
1. Introduction
Pre-trained neural language model은 엄청난 양의 in-depth knowledge를 학습한다.
이러한 parameterized된 implicit knowledge base 덕분에 외부 memory의 접근 없이도 사용할 수 있게 되었다.
하지만 이러한 모델들에는 다음과 같은 단점들이 존재하는데,
이 모델들은 본인의 memory를 쉽게 확장하거나 수정할 수 없고, 예측들에 대해 직관적으로 insight를 제공할 수 없으며 "hallucinations"들을 만들어 낼 수 있다.
parametric memory와 non-parametric (i.e., retrieval-based) memories들을 결합하는 Hybrid model들은 knowledge들을 직접 수정하고 확장할 수 있기 때문에 위와 같은 문제들을 다룰 수 있다.
또한 access된 knowledge는 inspected 될 수 있고 해석될 수 있다.
REALM과 ORQA 두 모델은 differentiable retriever를 사용한 masked language model을 결합하였는데,
좋은 성능을 보여주긴 하였지만 오로지 open-domain extractive question answering에 대해서만 연구되었다.
이 논문에서는 seq2seq 모델을 가져와 parametric과 non-parametric memory를 hybrid하였다.
parametric memory는 pre-trained seq2seq transformer를 사용하였고, non-parametric memory는 pre-trained retriever가 접근한 Wikipedia의 dense vector index를 사용하였다.
retriever는 input에 conditioned된 latent documents를 제공하고,
seq2seq 모델은 input에 대한 latent documents들을 condition하여 output을 만들어 낸다.
이 논문에서는 parametric과 non-parametric memory를 extensive knowledge를 사용하여 동시에 pre-trained되고 pre-loaded되도록 설계하였다.
결정적으로 이러한 mechanism을 사용하여 추가적인 훈련과정 없이 knowledge에 access할 수 있다.
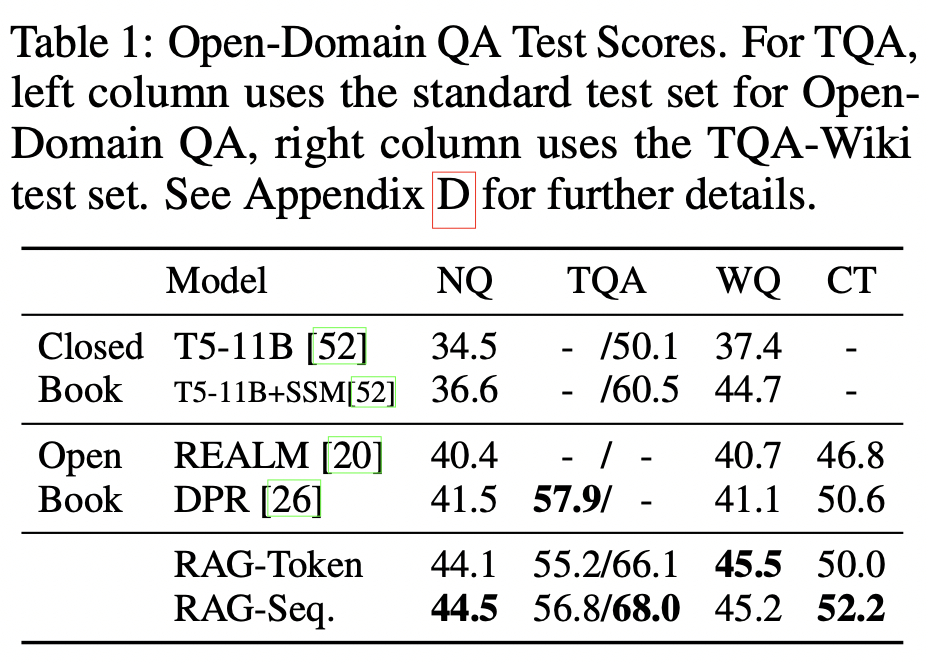
RAG 모델은 여러 QA task에서 SOTA의 성능을 보임을 확인하였다.
최종적으로 저자는 world change가 일어날 때, non-parametric memory를 바꿔줌으로써 model의 knowledge를 update 해줄 수 있음을 보여주었다.
2. Methods

RAG model은 input sequence x를 이용하여 text documents z를 검색하고, 이를 추가적인 context로 이용하여 target sequence y를 만들어 낸다.
Fig 1.에서 볼 수 있듯이, 모델은 아래 두가지의 components를 활용하게 되는데 :
(1) query x가 주어졌을 때 text passages에 대한 distributions을 return하는 retriever
(2) 이전 i-1개의 token y_(1:i-1)과 original input x, retrieved passage z의 context를 이용하여 current token을 만들어 내는 generator
retriever와 generator를 end-to-end로 train하기 위해 retrieved document를 latent variable로 취급하였다.
저자는 생성된 text에 대한 distribution을 만들어내기 위해 latent document를 제외시키는 두가지 model을 제시한다.
첫번째 approach인 RAG-Sequence 방법은 각각의 target token을 예측하기 위해 동일한 document를 사용하는 것이고,
두번째 approach인 RAG-Token 방법은 각각의 target token을 예측하기 위해 서로 다른 document에서 예측하는 것이다.
2.1 Models
RAG-Sequence Model
RAG-Sequence model은 온전한 sequence를 만들어내기 위해 동일한 retrieved document를 사용한다.
기술적으로 retrieved document를 single latent variable로 취급하고,
top-K approximation을 이용한 seq2seq 확률 p(y|x)을 얻기 위해 single latent variable을 marginalize 한다.

RAG-Token Model
RAG-Token 모델에서 저자는 각각의 target token을 위해 서로 다른 latent document를 이용할 수 있고, marginalize 할 수 있다.
이 방법은 generator가 answer를 만들어 낼 때 몇몇의 document로부터 content를 골라낼 수 있다.
구제적으로 top-K documents들은 retriever를 사용하여 검색되고, generator는 marginalizing하기 전이나 다음의 output token을 위한 과정을 반복하기 전에 각각의 document에 대한 다음 output token에 대한 distribution을 생성한다.

2.2 Retriever : DPR

d(z) : BERT_base로 이루어진 document encoder로 만들어낸 document의 dense representation
q(x) : BERT_base로 이루어진 query encoder가 만들어낸 query representation
pn(z|x) 확률을 가장 높게 하는 k개의 documents z의 list인 top-K (p(.|x))를 계산하기 위해 Maximum Inner Product Seart (MIPS)를 이용하고, 이는 sub-linear time에 근사하는 시간을 가진다.
이 논문에서는 pre-trained bi-encoder인 DPR을 사용하여 모델의 retriever를 초기화하고, document index를 만든다.
이 retriver는 TrivialQA question과 Natural Question들을 가지고 있는 document들을 검색하도록 훈련된다.
2.3 Generator : BART
Generator component는 임의의 encoder-decoder를 모델링함으로써 얻을 수 있다.
이 논문에서는 400M parameter를 가진 BART-LARGE(pre-trained seq2seq transformer)를 사용하였다.
BART를 이용하여 만들어 낼 때, input x와 retrieved content z를 결합하기 위해 단순히 그 둘을 concat한다.
이 논문에선 앞으로 BART generator parameter θ 를 parametric memory로 부르도록 한다.
2.4 Training
저자는 어떠한 document가 retrieved되어야 하는지 직접적인 supervision 없이 retriever와 generator가 동시에 훈련되도록 설계하였다.
input/output pairs (xj,yj)의 training corpus가 주어진 경우, stochastic gradient descent ADAM을 이용하여 각각의 target에 대한 negative marginal log-likelihood을 최소화 한다.

2.5 Decoding
test 시에 RAG-Sequence와 RAG-Token은 서로 다른 방법으로 argmax_y P(y|x)를 근사한다.
RAG-Token
RAG-Token 모델은 standard하고 autoregressive한 seq2seq generator로 볼 수 있고, 다음과 같은 transition 확률을 가진다.

decode하기 위해서는 위 언급된 확률을 standard beam decoder에 넣어 구한다.
RAG-Sequence
RAG sequence의 경우 likelihood p(y|x)는 전통적인 token당 likelihood로 깨지지 않으므로 single beam search로 해당 문제를 풀 수 없다.
각각의 document z에 대한 beam search로 실행하는 것 대신,
각각의 hypothesis를 확률 Pθ(yi | x,z,y_(1:i-1)) 을 이용하여 scoring한다.
이 방법은 hypotheses Y를 만들어 내는데, 이 중 일부는 모든 document의 beam에 나타나지 않았을 수 있다.
hypothesis y의 확률을 계산하기 위해 저자는 y가 beam에 나타나지 않는 각각의 document z에 대한 추가적인 forward pass를 실행시키고, generator 확률인 pn(z|x)를 곱한 후, marginal을 위한 beam에 대한 확률을 더한다.
더욱 효율적인 decoding을 위해, y가 x,zi로부터 beam search 하는 동안 생성되지 않은 y에 대해 pθ(y|x,zi)를 0으로 근사시킬 수 있다.
이 방법은 candidate Y 집합이 생성되었을 때 추가적인 forward passes들을 실행시킬 필요가 없게 만든다.
이 논문에서 이 decoding precedure를 "Fast Decoding"이라고 한다.
Results

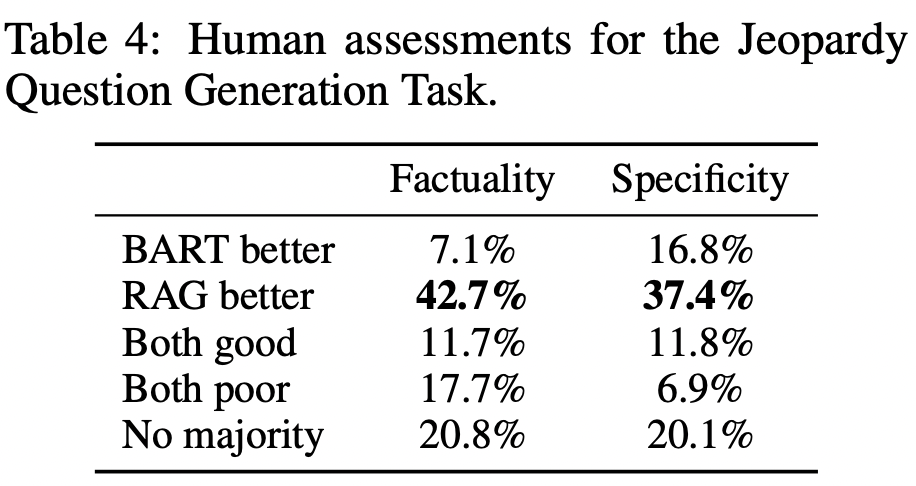
Conclusion
이 논문에서는 parametric 과 non-parametric memory에 접근하는 hybrid generation model을 제안하였다.
RAG model은 ODQA 부문에서 SOTA의 성능을 내는 것을 확인하였다.




댓글