https://arxiv.org/pdf/1910.13461.pdf
Abstract
이 논문에서는 'denoising autoencoder for pretraining sequence-to-sequence' model인 BART를 제안한다.
BART는 (1) 임의의 noising function을 이용하여 text를 corrupting하고, (2) original text를 reconstruct하도록 학습된다.
Introduction
Self-supervised 방법은 현재 폭넓은 NLP task에서 주목할만한 성능을 보이고 있다.
가장 성공적인 approaches는 MLM으로, masking된 text를 original text로 reconstruction 하도록 훈련되는 denoising autoencoder이다.
하지만 이러한 방법은 특정 task(e.g. span prediction, generatrion, etc.)에만 초점을 맞춘다는 단점이 존재한다.
따라서 이 논문에서는 BART 모델을 제안하였는데,
sequence-to-sequence model로 만들어진 denoising autoencoder로써 매우 넓은 end task에 적용가능하다.
Pretraining은 두 단계로 구성되어있다.
(1) 임의의 noising function을 이용하여 text을 corrupt한다.
(2) seq-to-seq model은 해당 text를 original text로 reconstruct하도록 학습된다.
이러한 방법의 key 장점은 바로 noising flexibility에 있다.
임의의 transformation은 original text에 적용할 수 있고, 해당 length도 바꾸어줄 수 있다.
실험을 통해 original sentences들의 순서를 random하게 섞고, 임의의 text 길이를 하나의 mask token으로 바꿔주는 과정이 가장 좋은 성능을 보였다고 말한다.

이러한 방법은 BERT에서 언급한 original word masking과 NSP 방법을 generalize한 것으로도 볼 수 있다.
이 방법은 model이 전체 문장길이에 대해 학습을 하고, input을 더욱더 transformation하게 만들어 줄 수 있다.
BART는 text generation 뿐만 아니라 comprehension task에서도 효과적으로 fine tuned될 수 있다.
이러한 BART는 Abstractive dialogue, QA, summarization task에서 새로운 SOTA의 성능을 내는 것을 확인하였다.
Model
BART는 corrupted된 document를 original document로 만들어주는 denoising autoencoder이다.
corrupted text를 bidirectional encoder(BERT)에 집어넣고,
left-to-right autoregressive decoder(GPT)가 이를 받는 구조로 구현되어 있다.
Architecture
BART는 standard Transformer architecture를 사용하였고, 대신 GPT부분에서는 ReLU 를 GeLUs로 바꾸고, N(0,0.02)로 parameter들을 초기화해준다.
BART의 구조는 BERT와 거의 유사한데, 몇가지 다른 부분이 있다.
(1) 각각의 decoder layer는 추가적으로 encoder의 final hidden layer와 cross-attention을 수행
(2) BERT는 word prediction 이전 과정에서 추가적인 feed-forward network를 사용하지만 BART에서는 사용 X
(BART에서는 encoder에서 바로 mask text를 예측하지 않음)
전체적으로 BART는 같은 size의 BERT model보다 10%정도 많은 parameter를 가지고 있다.
Pre-training BART
BART는 document를 corrupt하고, 디코더의 output과 original document 사이의 cross-entropy reconstruction loss를 optimizing 하도록 훈련이 진행된다.
또한 어떠한 document corruption에서도 적용가능하다고 하는데, 극단적으로 source에 대한 모든 정보가 없다고 하더라도 BART는 언어모델과 동일하게 동작한다고 한다.
아래는 이 논문에서 실험했던 transformation 기법에 대해 설명하고 있고, transformation 기법은 더 좋아질 potential이 존재한다고 한다.

Token Masking
BERT에서와 같이, random token들이 sample되고, [MASK] elements로 대체된다.
Token Deletion
input에서 random하게 token이 지워진다.
token masking과는 반대로, 모델은 무조건 missing input의 위치가 어디인지 정해주어야 한다.
Text Infilling
몇개의 text span들이 sample되고, span의 길이는 포아송 분포(λ=3)를 따른다.
각각의 span은 하나의 [MASK] token으로 대체되고, 0-length spandms [MASK] token을 집어넣는 것으로 대체한다.
text-infilling 과정에서는 모델이 얼마나 많은 token이 span을 통해 없어졌는지 예측하도록 학습되어야 한다.
Sentence Permutation
document는 마침표를 기준으로 해서 문장별로 분리되고, 이 문장들을 random한 순서로 섞는다.
Document Rotation
token은 동일한 확률로 random하게 선택되고, 해당 선택된 token이 document의 시작이 되도록 rotated된다.
이러한 task는 model이 document의 시작지점을 알아낼 수 있도록 훈련된다.
Fine-tuning BART
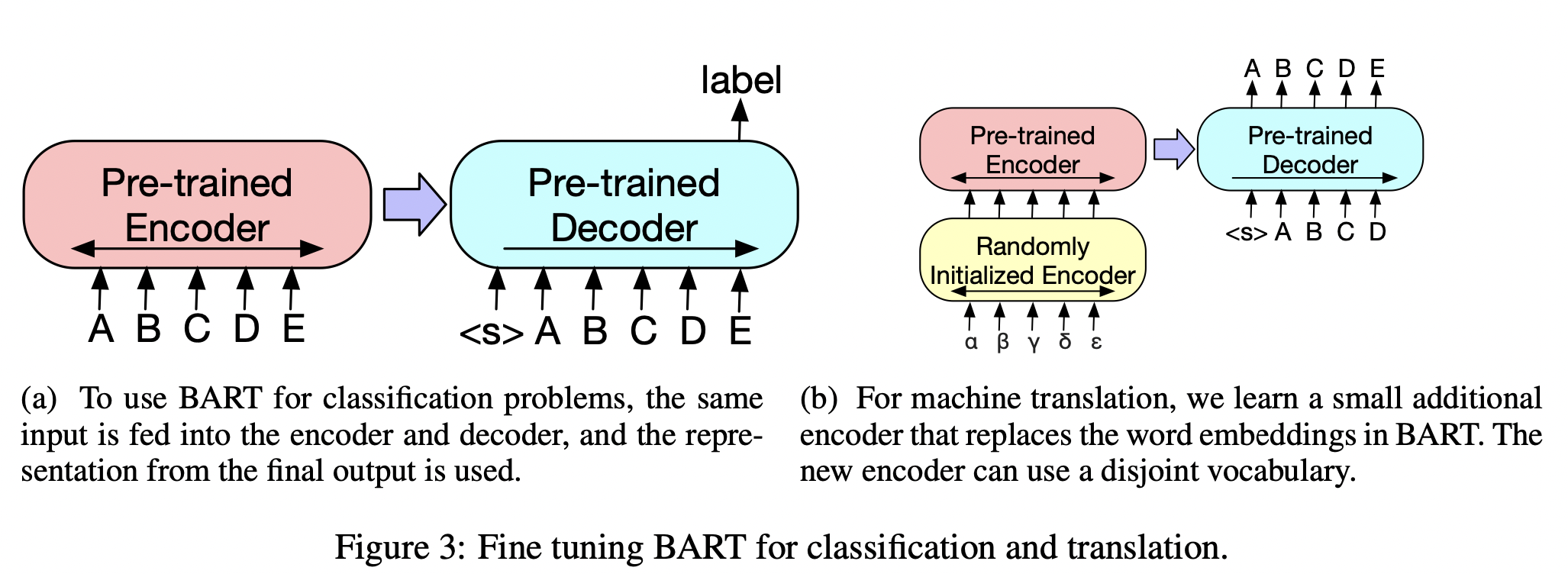
Sequence Classification Tasks
sequence classification task에서는 같은 input을 인코더와 디코더에 같이 넣어주고,
final 디코더 token의 final hidden state는 새로운 multi-class linear classifier에 입력된다.
이 방법은 BERT에서의 CLS token과 비슷한데, 여기서는 end에 추가적인 token을 넣어주어서 디코더에 있는 token에 대한 representation이 complete input으로부터 나온 decoder state와 attend 할 수 있도록 한다.(Fig 3.에서 확인 가능)
Token Classification Tasks
SQuAD 처럼 Answer endpoint classification과 같은 token classification task에서는
complete document를 인코더와 디코더 모두에 집어넣고,
디코더의 top hidden state를 각각의 word에 대한 representation으로 사용한다.
이러한 representation은 token을 classify하는데 사용한다.
Sequence Generation Tasks
BART가 autoregressive decoder이기 때문에, abstractive QA와 summarization 과 같은 sequence generation 에 대해 직접적으로 fine tuned 될 수 있다.
두 task 모두, information들은 manipulated된 input에서 copy되고, 이는 denoising pre-training objective와 매우 비슷하다.
여기서 encoder input은 input sequence가 되고, decoder 는 output을 autoregressively하게 생성해낸다.
Machine Translation
이전 연구에서는 pre-trained된 encoder를 결합함으로써 성능을 향상시켰다고 했지만, 이는 pre-trained language model의 decoder를 사용할 때는 이점이 제한되었다고 한다.
여기서 전체 BART 모델을 사용하여 single pretrained decoder가 MT 분야에 사용할 수 있고, 이는 bitext에서 학습된 새로운 encoder parameter set을 추가함으로써 가능해졌다고 한다.
더욱 정확하게는, BART의 encoder embedding layer를 new random하게 initialized된 encoder로 대체하였다고 한다.
모델은 인코더가 foreign word를 BART가 English로 denoise할 수 있는 input에 map하도록 훈련된다.
새로운 encoder는 기존 BART 모델과 분리된 단어들을 사용하여도 된다.
저자는 source encoder를 두가지 단계로 훈련시켰는데,
두가지 단계 모두 BART모델의 output으로부터 cross-entropy loss를 이용하여 backpropagating한다.
첫번째 단계에서는 저자는 대부분의 BART parameter를 freeze하고, only random하게 initialized된 source encoder, self-attention input projection matrix of BART's encoder first layer 일 때만 update 해준다.
두번째 단계에서는 모든 parameter를 적은 수의 iteration으로 학습시킨다.
Conclusion
이 논문에서는 corrupted document를 original로 map하는 pre-training approach인 BART를 제안하였다.
BART는 discriminative task에서 RoBERTa와 비슷한 성능을 보여주었고, 몇몇의 text generation task에는 새로운 SOTA급의 성능을 달성하였다.




댓글