https://arxiv.org/pdf/1704.00051.pdf
Abstract
이 논문에서는 Wikipedia의 정보들을 사용한 ODQA에 대해 제안한다.
machine reading at scale task의 경우 document retrieval (finding the relevant articles)와 machine comprehension of text (identifiying the answer spans from those articles)를 결합한 task이다.
bigram hashing과 TF-IDF matching을 사용하여 RNN 모델이 Wikipedia paragraphs에서 answer를 감지하도록 훈련시킨다.
Introduction
Wikipedia는 사람들이 흥미로워 할만한 최신 정보의 지식들을 가지고 있다.
위키피디아 articles들을 knowledge source로 사용하는 경우, large-scale ODQA와 text의 machine comprehension 두가지 문제를 동시에 다루어야 한다.
어떠한 질문에 대해 answer하기 위해 약 5백만개의 이상의 item중에서 관련성 있는 몇개의 articles들을 검색하고, answer를 확인하기 위해 신중히 그것들을 scan해주어야 한다.
저자는 이러한 setting을 machine reading at scale (MRS)라고 명명하였다.
IBM의 deepQA와 같은 large-scale QA의 경우 answer하기 위해 Wikipedia 뿐만 아니라 dictionaries, new articles들과 같은 곳에서 답변을 찾는다.
때문에 이런 시스템은 더 정확히 답변하기 위해 information redundancy에 크게 의존하게 된다.
single knowledge source는 evidence가 한번만 나타날 수 있기 때문에, 답을 찾아가는 동안 모델이 매우 정확하게 훈련되도록 강요된다.
MRS는 large open source에 대한 searching의 realistic constraint를 지키면서 text에 대한 deep understanding을 필요로하는 machine comprehension을 동시에 유지하는 것에 초점을 맞춘다.
이 논문에서 제안된 DrQA는 다음과 같은 요소로 구성되어 있다.
(1) Document Retriever
question이 주어지면 관련된 articles의 하위 집합을 bigram hasing과 TF-IDF matching을 사용하여 반환하도록 설계되었다.
(2) Document Reader
RNN machine comprehension model이 Retriever에서 return된 document들에서 answer의 span들을 얻어낼 수 있도록 훈련된다.
실험을 통해 해당 모델이 Wikipedia의 내장 검색 엔진보다 더욱 성능이 좋았고, SQuAD benchmark에서도 SOTA의 성능을 보였다는 것을 확인하였다.

Our System : DrQA
Document Retriever
기본적인 QA system 다음으로, 저자는 머신러닝을 사용하지 않은 효율적인 document retrieval system을 사용하여 search space를 좁히고, 관련될 가능성이 높은 articles들만 읽는데에 초점을 맞춘다.
Articles과 questions들은 TF-IDF를 이용하여 비교되고, 시스템을 더욱 효율적으로 하기 위해 n-gram feature를 사용하여 local word order를 고려하도록 하였다.
DrQA는 Document Retriever를 전체 모델의 첫부분으로 사용하였고, 어떤 question이 들어왔을 때 5개의 Wiki articles를 반환하도록 하였고, 반환된 articles들은 다음 Reader에서 가공된다.
Document Reader
l개의 token으로 구성된 question q ={q1,...,ql}이 주어지고, 하나의 document나 n개의 paragraph로 구성된 document의 집합 (m개의 token으로 구성된 하나의 paragraph p = {p1,...,pm}) 이 주어진 경우에 저자는 각각의 paragraph에 차례로 적용할 수 있고, 최종적으로 예측된 answer를 모을 수 있도록 RNN model을 개발하였다.
Paragraph encoding
먼저 paragraph p의 모든 tokens pi를 feature vector sequence pi로 변환하고, 이를 RNN의 Input으로 집어넣는다.

이 과정에서 pi는 주변의 유용한 context information을 encoding할 것으로 예상된다.
여기서 저자는 LSTM을 사용하였고, 마지막에는 각 layer의 hidden unit의 concat으로 pi를 사용하였다.
feature vector ~pi는 다음과 같은 부분으로 구성된다.
- Word Embeddings
- Exact match
- Token features
저자는 또한 token pi의 part-of-speech (POS), named entity recognition (NER) tags, term freqeuncy (TF)와 같은 일부 특성들을 context에 반영하는 몇몇의 manual feature들을 추가하였다.
-Aligned question embedding
최종 part에서 저자는 aligned question embedding 부분을 결합하였다. 해당 부분에서는 pi와 각각의 question word인 qj 사이의 유사성을 포착하기 위한 attention score a_i,j를 구하도록 하였다.

alpha() : single dense layer with ReLU nonlinearity
Question encoding
question encoding은 더욱 간단한데
단지 또다른 RNN을 qi의 word embedding의 가장 위에 적용하고, 결과로 나온 hidden unit을 하나의 single vector로 변환하는 과정을 거친다.

single vector q는 다음과 같은 공식으로 구한다.
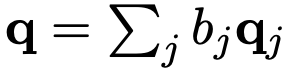
이때 bj는 각각 question의 중요도를 의미하는데 다음과 같은 공식으로 구할 수 있다.

W : weight vector to learn
Prediction
paragraph level에서의 목표는 token의 spans이 correct answer와 거의 일치하도록 예측하는 것이다.
paragraph vector {p1,...,pm}과 question vector q를 input으로 집어넣고, 두개의 ends of the span을 예측하기 위해 두개의 classifiers를 독립적으로 훈련시킨다.
구체적으로 pi와 qi 사이의 유사성을 포착하기 위해 bilinear term을 사용하고, 각각의 token의 시작과 끝에 대한 확률을 다음과 같이 구한다.
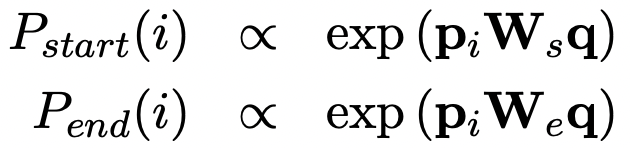
예측 과정속에서, 저자는 i <= i' <= i+15이면서 P_start(i) X P_end(i')의 확률을 가장 크게하는 best span을 고를 수 있도록 하였다.
Results


Conclusion
이 논문에서는 scale에 관한 machine reading task에서 Wikipedia라는 unique한 knowledge source를 ODQA에 사용하였다.
또한 MRS가 연구자들이 focus on 해야할 key challenging task임을 말한다.




댓글