https://arxiv.org/pdf/1906.00300.pdf
Abstract
ODQA에서 evidence 후보들을 검색하기 위해 'information retrieval(IR)' system을 사용하고 있지만 gold evidence가 항상 available하지 않을 뿐더러 QA는 근본적으로 IR과 다르기 때문에 이 방법은 sub-optimal하다.
이 논문에서는 IR system 없이 Question-Answer string pair를 이용하여 Retriever와 Reader를 같이 학습하는 것이 가능하다는 것을 처음 보여준다.
이러한 setting에서 모든 Wikipedia로부터 evidence retrieval은 latent variable로 여겨지고,
scratch부터 학습하는 것은 비현실적이기 때문에, 'Inverse Cloze Task'를 이용하여 retriever를 pre-train한다.
Introduction
IR 시스템은 gold evidence를 대신해 evidence 후보들을 만들어 낸다.
weakly supervised setting에서 strong supervision 사이의 dependency는 IR 시스템이 만들어낸 noisy gold evidence를 추정하는 과정에서 사라지게 된다.
하지만 QA는 근본적으로 IR과 다르다.
IR은 lexical and semantic matching을 고려하는 반면, question은 사용자가 명시적으로 unknown information을 찾으려 하기 때문에 더 많은 language understanding이 필요하다.
이 논문에서는 최초의 Open-Retrieval Question Answering system(ORQA)을 제시한다.
ORQA는 open corpus에서 evidence를 검색하도록 학습하고, 오로지 Question-Answer string pairs에 의해서만 supervised된다.
이 논문에서의 key insight는 만약 unsupervised Inverse Cloze Task(ICT)를 이용하여 retriever를 pretrain하는 경우 end-to-end learning이 가능해진다는 것이다.
ICT에서 문장은 pseudo-question으로 여겨지며, 해당 context는 pseudo-evidence로 여겨진다.
pseudo-question이 주어진 경우, ICT는 batch에 있는 후보군들 속에서 pseudo-question과 대응하는 psudo-evidence를 선택한다.
Overview
이 section에서는 ODQA에 대한 notation을 정리한다.
Task
q : question string
a : answer string
Formal Definitions
Model은 unstructured text corpus로 정의되는데, 이때 evidence texts로 구성된 B개 Block로 split된다.
answer derivation은 (b,s)로 표현되는데, s는 text span을 의미한다.
span s의 시작과 끝은 START(s), END(s)로 표기한다.
S(b,s,q) : 모델의 scoring function으로 question q가 주어졌을 때 answer derivation (b,s)의 goodness를 의미
scoring function은 아래와 같이 두개의 term으로 다시 나뉘어짐

S_retr : retrieval component
S_read : reader component
inference 과정에서 model은 가장 높은 scoring derivation의 answer string을 output으로 한다.

TEXT(b,s) : answer derivation (b,s)를 answer string으로 map
Existing Pipelined Models
Open-Retrieval Question Answering

ORQA의 가장 중요한 측면은 ORQA의 expressivity이다.
이는 blackbox IR system에 의해 return된 closed set으로 제한되지 않고, open corpus에서 어떠한 text든 검색할 수 있는 능력을 의미한다.
최근 transfer learning이 발전하고 있음에 따라, 모든 scoring compoenets는 BERT로부터 유도된다.
BERT function은 아래와 같이 나타낼 수 있다.

BERT는 1개나 2개의 string을 argument로 가지고, CLS pooling token이나 input token에 대응하는 vector를 return 한다.
Retriever component
retriever가 learnable하게 하기 위해, 저자는 retrieval score를 question q와 evidence block b의 dense vector representation들 사이의 inner product로 정의하였다.

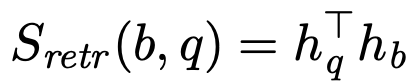
Reader component
reader는 BERT에서 제안된 reading comprehension model의 span-based variant이다.

이때 span은 end point들의 concat이고, start/end interaction을 가능하게 하기 위한 MLP로 score를 매긴다.
Inference & Learning Challenges
위 언급된 model은 개념적으로는 simple하다.
하지만 inference 와 learning 과정에서는 다음과 같은 challenging이 있다.
(1) open evidence corpus는 엄청난 양(over 13 million evidence blocks)의 search space를 제공한다.
(2) 이러한 space를 탐색하는 방법이 완전히 latent하기 때문에, 일반적인 teacher-forcing approaches는 적용되지 않는다.
Latent-variable 방법은 또한 많은 ambiguous derivation들로 인해 적용하기가 굉장히 어렵다.

예를 들어 Table 2.에 보여진 것처럼 Wiki에 있는 많은 관련없는 passages들은 "seven"이라는 answer string을 포함하고 있을 수 있다.
저자는 이러한 문제를 unsupervised pre-training을 이용한 retriever를 초기화하면서 다루도록 하였다.
pretrained retriever는 (1) Wiki의 모든 evidence block를 pre-encode할 수 있게 하고, dynamic하지만 빠른 top-k retrieval이 가능하도록 하거나, (2) spurious ambiguities로부터 멀리하기 위한 bias를 줄 수 있다.
Inverse Cloze Task
여기서 제안하는 pre-training의 목표는 retriever가 QA에 대한 evidence retriever와 매우 유사한 unsupervised task를 풀도록 하는 것이다.
직관적으로 유용한 evidence는 보통 entities, events, 그리고 question으로부터 relations에 대해 말하는 것이다. 이는 또한 question에서 언급하지 않은 extra information을 포함하고 있을 수 있다.
Question-evidence pair의 unsupervised analog는 sentence-context pair이다.
sentece의 context는 semantically하게 relevant하고, sentence의 missing information을 추론할 수도 있다.
위와 같은 근거로 저자는 pre-train retrieval module인 Inverse Cloze Task(ICT)를 제안한다.
일반적인 Cloze task에서는 context를 이용하여 mask된 text를 예측하는 것인데,
ICT는 sentence가 주어진 경우 그것의 context를 예측하도록 한다.

저자는 donwstream retrieval과 유사한 discriminative objective를 아래와 같이 사용한다.

q : pseudo-question으로 다루어지는 random sentence
b : q 주위의 text
BATCH : negative sample로 사용되는 batch의 evidence block 집합
ICT의 중요한 점은 pseudo-question이 evidence에 존재하지 않기 때문에, word matching features들보다 더욱 많은 학습을 필요로 한다는 것이다.
예를들어, Fig 2.에 있는 pseudo-question은 절대로 명시적으로는 "Zebras"를 언급하지 않지만, retriever는 Zebras를 다루는 context를 고를 수 있어야 할 것이다.
under-specified language속에서 의미를 추론할 수 있어야 한다는 것이 IR과 QA의 다른점이라고 할 수 있다.
하지만 저자는 또한 retriever가 word matching을 배우는 것을 원하지 않는데, lexical overlap은 궁극적으로 retrieval에서 매우 유용한 feature이기 때문이다.
그러므로 여기서는 context로부터 example의 90%에 해당하는 문장을 제거하여 모델이 필요로 할 때 abstract representation을 배우도록 하고, available할 때 low-level word matching을 배우도록 한다.
ICT pre-training은 다음과 같은 두개의 main 목표를 이루었다.
1. fine-tuning 과정에서의 question과 pre-training 과정에서의 sentence들 사이의 mismatch가 있을지라도,
저자는 latent-variable learning을 bootstrapping하기에 충분하도록 zero-shot evidence retrieval performance를 기대
2. downstream에서의 evidence block과 pre-trained된 evidence block 사이에는 저런 mismatch가 발생하지 않는다.
따라서 저자는 block encoder BERT_B(b)가 '추가된 training 없이' 잘 수행되는 것을 기대하였다.
오로지 question encoder만 downstream data에 따른 fine-tuned이 필요하다.
위 두가지 특성은 computationally feasible inference와 end-to-end learning을 가능케 하는데 매우 중요하다.
Inference
fixed block encoder가 검색에 유용한 representation을 제공하기 때문에 evidence corpus에 있는 모든 block encodings을 pre-compute 할 수 있다.
결과적으로 엄청난 양의 evidence block은 fine-tuning하는 동안에는 re-encoded가 필요하지 않고, Locality Sensitive Hashing과 같은 tools들을 이용하여 pre-compile 할 수 있다.
pre-compiled index 안에서 inference는 standard beam-search procedure를 따른다.
저자는 top-k의 evidence block을 검색하고, 오로지 k개의 block으로부터 expensive reader score를 계산한다.
Learning
Learning은 매우 직관적인데, ICT가 non-trivial zero-shot retrieval을 제공해야 하기 때문이다.
먼저 answer derivation에 대한 distribution을 다음과 같이 정의하였다.

TOP(k) : S_retr에 기초한 top k개의 retrieved block (이 논문에서는 k=5로 설정하여 실험하였다.)
gold answer string a가 주어진 경우에 저자는 beam을 이용하여 모든 correct derivation을 찾고, 그것들의 marginal log-likelihood를 최적화한다.

a = TEXT(s) : answer string a가 span s과 정확히 일치하는 것을 의미
더욱 적극적인 learning을 위해, 초기의 update를 추가하여 더 많은 c개의 evidence blocks들을 고려할 수 있도록 할 뿐만 아니라 계산할때 더욱 cheap하게 retrieval score를 update 할 수 있다.

최종 loss는 다음과 같다.

만약 알맞은 answer를 전혀 찾지 못한 경우에는 example들이 모두 제거된다.
저자는 random initialization 때문에 거의 모든 example들이 제거될 것이라고 예측하였지만, ICT pre-training 덕분에 실제에서는 10%보다 낮은 정도의 examples들만 제거되었다.
앞에서 언급한 것처럼 evidence block encoder에 들어있는 parameter들을 제외한 모든 parameter를 fine-tune한다.
query encoder가 trainable하기 때문에 모델은 potentially하게 어떠한 evidence block들을 검색할 수 있도록 학습할 수 있다.
이러한 expressivity는 IR system과는 매우 다른 점이다.
Result



Conclusion
이 논문에서는 ORQA를 제안하여 IR 시스템 없이 오로지 question-answering pair만을 이용하여 end-to-end하게 학습될 수 있도록 하였다.




댓글