https://arxiv.org/pdf/1908.08345.pdf
Abstract
BERT는 최근 넓은 NLP 분야에서 성능을 크게 향상시킨 모델이다.
이 논문에서는 BERT 모델을 어떻게 text summarization task에 적용할지와 extractive / abstractive summarization에 대한 model을 제안한다.
최신의 document-level encoder를 추가하여 BERT가 document의 semantics들을 표현하고, 각각의 문장들의 표현을 가지고 있을 수 있도록 설계하였다.
Extractive model에서는 해당 encoder의 가장 윗단에 몇개의 intersentence Transformer layer를 추가하였다.
Abstractive model에서는 새로운 fine-tuning schedule을 제안하여 encoder와 decoder에 있는 서로 다른 optimizer에 적용시킬 수 있도록 하고, model이 만들어낸 summaries들의 quality를 크게 향상시킬 수 있는 two-staged fine-tuning approach를 제시한다.
Introduction
Language model pretraining 기법은 많은 분야의 NLP task에서 성능을 크게 향상시켰다.
특히 BERT model은 word와 sentence representation들을 very large transformer에서 combine한다. 이 과정에서 방대한 양의 text로 MLM이나 NSP(Next Sentence Prediction) 방법을 통해 pretrained되고, 다양한 task로 fine-tuned 된다.
이렇게 pretrained language model 들은 보통 NLU problem이나 classification task에서 사용되지만, 이 논문에서는 text-summarization에 미치는 영향을 조사하도록 한다.
이전 task와는 달리 summarization task는 words나 sentences 각각의 의미를 알아내는 것과는 달리, 전체적인 맥락을 이해할 수 있는 NLU를 필요로 한다.
결국 summarization은 document의 의미를 가장 잘 유지하면서 document를 더 짧은 버전으로 압축하는 것이 목표이다.
abstractive summarization 관점에서는 source text에 없는 새로운 단어들을 이용하여 summary를 create 하는 문제로 정의할 수 있고, extractive summarization 관점에서는 해당 sentence가 summary에 포함되어야 하는 label을 가지고 있는지 아닌지를 파악하는 binary classification 문제로 정의할 수 있다.
이 논문에서는 BERT를 text summarization에 적용하기 위해 document level encoder를 사용하여 document를 encode하고, 각각의 sentence에 대한 표현을 가질 수 있도록 하였다.
extractive model의 경우 encoder 위에 몇 겹의 intersentence transformer layers들을 쌓아 sentence에서 뽑아낸 document-level features들을 얻을 수 있도록 한다.
abstractive model의 경우 pretrained BERT encoder와 random하게 initialized된 transformer decoder를 결합한 encoder-decoder architecture를 채택하였다.
Background
Pretrained Language Models

general architecture of BERT를 먼저 살펴보자면,
1. Input text가 두개의 special token에 삽입되면서 첫번째로 pre-processing 된다.
[CLS] 는 text의 처음을 나타내는 token으로 삽입되고, 이 token의 output은 전체 sequence의 정보를 결합한 것이 된다.(for classification tasks)
2. [SEP] token은 각각의 sentence 끝에 넣어 sentence의 boundary를 표시하는 역할을 한다.
modified text는 token의 sequence X = [w1,w2, ... , w_n]으로 표현되고, 각각의 token w_i는 다음과 같은 3가지의 embedding 종류를 가진다.
- token embedding : 각각 token의 의미를 가리킴
- segmentation embedding : 두 sentence 사이를 구별하기 위해 사용된다.
- position embedding : text sequence에서 각각의 token의 위치를 의미한다.
이러한 3가지의 embeddings 들은 input vector x_i에 더해지고, bidirectional Transformer with multiple layers에 넣어진다.
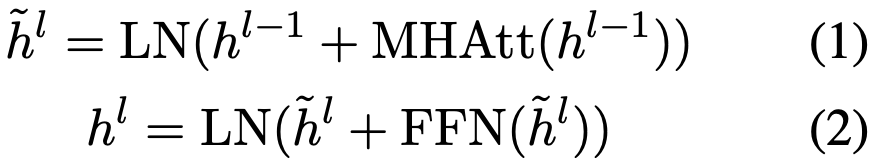
top layer에서 BERT는 rich information 속에서 각각의 token의 output vector t_i를 만들어 낸다.
Fine-tuning BERT for Summarization
Summarization Encoder
지금까지 BERT는 다양한 NLP task에서 사용되었지만, summarization 부문에서는 널리 활용되지 않았다.
BERT 자체가 masked-language model로 학습되었기 때문에, output vector가 sentence 대신 token 단위로 이루어져 있고, 이는 sentence-level로 표현되어야 하는 summarization 분야와 맞지 않다.
따라서 individual sentences를 표현하기 위해, [CLS] token을 각각의 sentence 앞에 넣고, 각각의 [CLS] token이 sentence feature를 가질 수 있도록 한다.
또한 interval segment embedding을 사용하여 document 안에 있는 multiple sentences들을 구별할 수 있게 한다.
예를 들어 짝수번째 문장은 E_A로, 홀수번째 문장은 E_B로 segment embedding을 해주는 방식으로
document = [sent1, sent2, sent3, sent4, sent5]로 구성되어 있다면, [Ea,Eb,Ea,Eb,Ea]와 같이 embedding을 배정해 줄 수 있다.
이 방법을 사용하면 document를 hierarchically하게 학습할 수 있는데, lower Transformer layer에서는 인접 sentences들을 표현할 수 있는 반면 higher layer에서는 self-attention의 combination으로 이루어져 있기 때문에 여러 문장이 결합된 담화를 표현할 수 있다.
BERT model의 positional embedding의 경우 최대 512개의 token을 가질 수 있었는데, 이러한 limitation을 randomly하게 초기화되고, encoder에 있는 다른 parameter에 대해 fine-tuned된 position embedding을 더 추가함으로써 해결할 수 있었다고 한다.
Extractive Summarization
document d = [sent1, sent2, ... , sent_m] 라 하자
Extractive summarization은 각각의 sent_i가 summary에 포함되어야 할지 아닐지에 대한 label 배정하는 task로 정의할 수 있다.
BERTSUM model에서 가장 top layer에 있는 i번째 [CLS] symbol이 나타내는 vector t_i가 sent_i를 나타내는 representation으로 사용될 수 있다.
몇몇의 inter-sentence transformer layers들은 BERT ouput의 가장 위에 쌓이면서 document-level feature를 포착한다.

h^0 = PosEmb(T)
T : BERTSUM의 sentence vectors output
PosEmb : sinusoid positional embedding to T

(h_i)^L : transformer의 L-th layer를 통과한 sent_i vector
L = 1, 2, 3일 때를 실험해 보았을 때 L=2일 때 가장 성능이 좋았다고 한다. => BERTSUMEXT model
Loss는 해당 token의 label y_i에 대한 binay classification entropy loss 를 사용하였다.
Abstractive Summarization
abstractive summarization을 위해 standard encoder-decoder framework를 사용하였다.
encoder는 pretrained BERTSUM encoder를 사용하였고, decoder는 random하게 initialized된 6-layered Transformer를 사용하였다.
하지만 여기서 encoder와 decoder 사이에 mismatch가 있다고 생각할 수 있는데, 이는 전자는 pretrained된 반면, 후자는 scratch부터 train 해주어야 하기 때문이다.
이러한 방법은 fine-tuning을 unstable하게 만들 수 있는데,
예를 들어 encoder는 특정 data에 overfit 되어 있을 수 있지만, decoder는 반대로 underfit 되어 있을 수 있기 때문이다. (반대의 경우도 가능)
이 현상을 회피하기 위해 이 논문에서는 새로운 fine-tuning schedule를 design 했고, encoder와 decoder의 optimizer를 분리하였다.
두 optimizer의 beta 값을 다르게 하고, warmup step과 learning rate도 다르게 설정하였다.
pretrained encoder는 더욱 작은 learning rate + smoother decay를 가지고 있어야 한다.
추가적으로 two-stage fine-tuning approach를 제안하여 처음에는 encoder가 extractive summarization task에 적용할 수 있도록 fine-tune해주고, 그 후에 abstractive summarization task에 fine-tune 해준다.
결국 extractive objectives를 사용하는 것이 abstractive summarization의 성능도 boost 할 수 있다고 말한다.
또한 two-stage approach가 컨셉적으로 매우 간단하고, model이 근본적으로 각각의 architecture를 바꾸지 않으면서 두 task 사이의 information을 공유할 수 있다는 장점이 있다고 말한다.
abstractive model을 BERTSUMABS라 하고, two-stage fine-tuned model을 BERTSUMEXTABS라 한다.
Conclusion
이 논문에서는 pretrained BERT가 text summarization에 효과적으로 적용될 수 있음을 보여주었다.
novel document-level encoder와 abstractive / extractive summarization의 general framework를 제시하였다.
Experimental result를 보았을 때 계산된 평가지표와 human-based evaluation 모두 SOTA의 성능을 내었다.




댓글