반응형
# models.py
import torch.nn as nn
import torch.nn.functional as F
import torch
from torchvision.models import vgg19
import math
class FeatureExtractor(nn.Module):
def __init__(self):
super(FeatureExtractor, self).__init__()
vgg19_model = vgg19(pretrained=True)
self.feature_extractor = nn.Sequential(*list(vgg19_model.features.children())[:18])
#block 3까지 통과시킨 feature
def forward(self, img):
return self.feature_extractor(img)
#block 3까지 통과시킨 feature 출력
# Sequential(
# (0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (1): ReLU(inplace=True)
# (2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (3): ReLU(inplace=True)
# (4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
# block 1
# (5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (6): ReLU(inplace=True)
# (7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (8): ReLU(inplace=True)
# (9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
# block 2
# (10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (11): ReLU(inplace=True)
# (12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (13): ReLU(inplace=True)
# (14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (15): ReLU(inplace=True)
# (16): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (17): ReLU(inplace=True)
# (18): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
# block 3
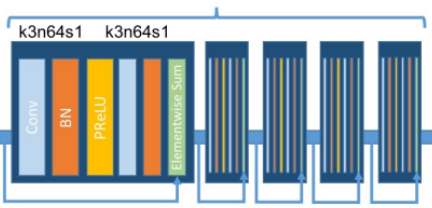
class ResidualBlock(nn.Module):
def __init__(self, in_features):
super(ResidualBlock, self).__init__()
self.conv_block = nn.Sequential(
nn.Conv2d(in_features, in_features, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(in_features, 0.8),
nn.PReLU(),
nn.Conv2d(in_features, in_features, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(in_features, 0.8),
)
def forward(self, x):
return x + self.conv_block(x)
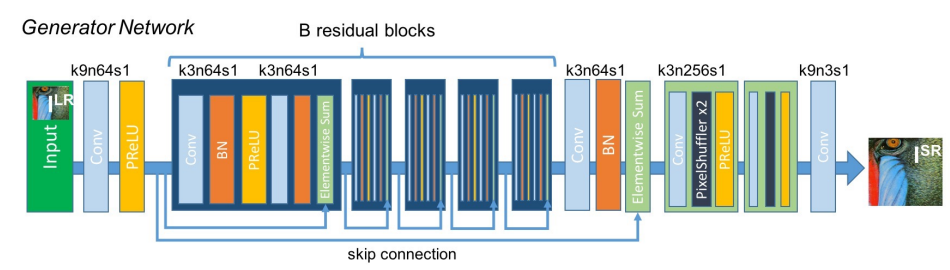
class GeneratorResNet(nn.Module):
def __init__(self, in_channels=3, out_channels=3, n_residual_blocks=16):
super(GeneratorResNet, self).__init__()
# First layer
self.conv1 = nn.Sequential(nn.Conv2d(in_channels, 64, kernel_size=9, stride=1, padding=4), nn.PReLU())

# Residual blocks
res_blocks = []
for _ in range(n_residual_blocks):
res_blocks.append(ResidualBlock(64)) # 입력 feature : 64
self.res_blocks = nn.Sequential(*res_blocks)
# Second conv layer post residual blocks
self.conv2 = nn.Sequential(nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=1), nn.BatchNorm2d(64, 0.8))
# 나중에 forward에서 덧셈 연산 수행

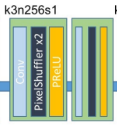
# Upsampling layers
upsampling = []
for out_features in range(2):
upsampling += [
# nn.Upsample(scale_factor=2),
nn.Conv2d(64, 256, 3, 1, 1),
nn.BatchNorm2d(256),
nn.PixelShuffle(upscale_factor=2),
nn.PReLU(),
]
self.upsampling = nn.Sequential(*upsampling)
# Final output layer
self.conv3 = nn.Sequential(nn.Conv2d(64, out_channels, kernel_size=9, stride=1, padding=4), nn.Tanh())
def forward(self, x):
out1 = self.conv1(x)
out = self.res_blocks(out1)
out2 = self.conv2(out)
out = torch.add(out1, out2) # Residual block 끝난 뒤 element-wise sum 수행
out = self.upsampling(out)
out = self.conv3(out)
return out
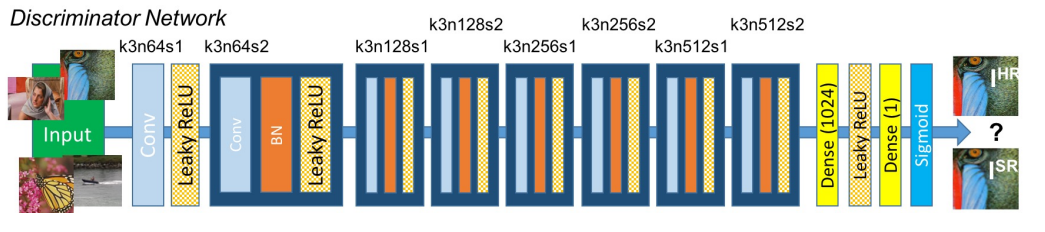
class Discriminator(nn.Module):
def __init__(self, input_shape):
super(Discriminator, self).__init__()
self.input_shape = input_shape
in_channels, in_height, in_width = self.input_shape
patch_h, patch_w = int(in_height / 2 ** 4), int(in_width / 2 ** 4)
self.output_shape = (1, patch_h, patch_w)
def discriminator_block(in_filters, out_filters, first_block=False):
layers = []
layers.append(nn.Conv2d(in_filters, out_filters, kernel_size=3, stride=1, padding=1))
if not first_block: # 두번째 block 부터 BN layer 추가
layers.append(nn.BatchNorm2d(out_filters))
layers.append(nn.LeakyReLU(0.2, inplace=True))
layers.append(nn.Conv2d(out_filters, out_filters, kernel_size=3, stride=2, padding=1))
layers.append(nn.BatchNorm2d(out_filters))
layers.append(nn.LeakyReLU(0.2, inplace=True))
return layers
layers = []
in_filters = in_channels
for i, out_filters in enumerate([64, 128, 256, 512]):
layers.extend(discriminator_block(in_filters, out_filters, first_block=(i == 0)))
in_filters = out_filters
layers.append(nn.Conv2d(out_filters, 1, kernel_size=3, stride=1, padding=1))
self.model = nn.Sequential(*layers)
def forward(self, img):
return self.model(img)
------------------------------------------------------------------
"""
Super-resolution of CelebA using Generative Adversarial Networks.
The dataset can be downloaded from: https://www.dropbox.com/sh/8oqt9vytwxb3s4r/AADIKlz8PR9zr6Y20qbkunrba/Img/img_align_celeba.zip?dl=0
(if not available there see if options are listed at http://mmlab.ie.cuhk.edu.hk/projects/CelebA.html)
Instrustion on running the script:
1. Download the dataset from the provided link
2. Save the folder 'img_align_celeba' to '../../data/'
4. Run the sript using command 'python3 srgan.py'
"""
import argparse
import os
import numpy as np
import math
import itertools
import sys
import torchvision.transforms as transforms
from torchvision.utils import save_image, make_grid
from torch.utils.data import DataLoader
from torch.autograd import Variable
from models import *
from datasets import *
import torch.nn as nn
import torch.nn.functional as F
import torch
os.makedirs("images", exist_ok=True)
os.makedirs("saved_models", exist_ok=True)
parser = argparse.ArgumentParser()
parser.add_argument("--epoch", type=int, default=0, help="epoch to start training from")
parser.add_argument("--n_epochs", type=int, default=200, help="number of epochs of training")
parser.add_argument("--dataset_name", type=str, default="img_align_celeba", help="name of the dataset")
parser.add_argument("--batch_size", type=int, default=4, help="size of the batches")
parser.add_argument("--lr", type=float, default=0.0002, help="adam: learning rate")
parser.add_argument("--b1", type=float, default=0.5, help="adam: decay of first order momentum of gradient")
parser.add_argument("--b2", type=float, default=0.999, help="adam: decay of first order momentum of gradient")
parser.add_argument("--decay_epoch", type=int, default=100, help="epoch from which to start lr decay")
parser.add_argument("--n_cpu", type=int, default=8, help="number of cpu threads to use during batch generation")
parser.add_argument("--hr_height", type=int, default=256, help="high res. image height")
parser.add_argument("--hr_width", type=int, default=256, help="high res. image width")
parser.add_argument("--channels", type=int, default=3, help="number of image channels")
parser.add_argument("--sample_interval", type=int, default=100, help="interval between saving image samples")
parser.add_argument("--checkpoint_interval", type=int, default=-1, help="interval between model checkpoints")
opt = parser.parse_args()
print(opt)
cuda = torch.cuda.is_available()
hr_shape = (opt.hr_height, opt.hr_width)
# ,odels.py에서 가져옴
generator = GeneratorResNet()
discriminator = Discriminator(input_shape=(opt.channels, *hr_shape))
feature_extractor = FeatureExtractor()
# Set feature extractor to inference mode
feature_extractor.eval()
# Losses
criterion_GAN = torch.nn.MSELoss()
criterion_content = torch.nn.L1Loss()
if cuda:
generator = generator.cuda()
discriminator = discriminator.cuda()
feature_extractor = feature_extractor.cuda()
criterion_GAN = criterion_GAN.cuda()
criterion_content = criterion_content.cuda()
if opt.epoch != 0:
# Load pretrained models
generator.load_state_dict(torch.load("saved_models/generator_%d.pth"))
discriminator.load_state_dict(torch.load("saved_models/discriminator_%d.pth"))
# Optimizers
optimizer_G = torch.optim.Adam(generator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
Tensor = torch.cuda.FloatTensor if cuda else torch.Tensor
dataloader = DataLoader(
ImageDataset("../../data/%s" % opt.dataset_name, hr_shape=hr_shape),
batch_size=opt.batch_size,
shuffle=True,
num_workers=opt.n_cpu,
)
# ----------
# Training
# ----------
for epoch in range(opt.epoch, opt.n_epochs):
for i, imgs in enumerate(dataloader):
# Configure model input
imgs_lr = Variable(imgs["lr"].type(Tensor))
imgs_hr = Variable(imgs["hr"].type(Tensor))
# Adversarial ground truths
valid = Variable(Tensor(np.ones((imgs_lr.size(0), *discriminator.output_shape))), requires_grad=False)
fake = Variable(Tensor(np.zeros((imgs_lr.size(0), *discriminator.output_shape))), requires_grad=False)
# ------------------
# Train Generators
# ------------------
optimizer_G.zero_grad() #gradient 초기화
# LR image를 Generator에 넣어 HR image 생성
gen_hr = generator(imgs_lr)
# Adversarial loss
loss_GAN = criterion_GAN(discriminator(gen_hr), valid)
# Content loss
gen_features = feature_extractor(gen_hr)
real_features = feature_extractor(imgs_hr)
loss_content = criterion_content(gen_features, real_features.detach())
# Total loss
loss_G = loss_content + 1e-3 * loss_GAN
loss_G.backward() #loss update
optimizer_G.step()
# ---------------------
# Train Discriminator
# ---------------------
optimizer_D.zero_grad()
# Loss of real and fake images
loss_real = criterion_GAN(discriminator(imgs_hr), valid)
loss_fake = criterion_GAN(discriminator(gen_hr.detach()), fake)
# Total loss
loss_D = (loss_real + loss_fake) / 2
loss_D.backward()
optimizer_D.step()
# --------------
# Log Progress
# --------------
sys.stdout.write( #training 현황 출력
"[Epoch %d/%d] [Batch %d/%d] [D loss: %f] [G loss: %f]"
% (epoch, opt.n_epochs, i, len(dataloader), loss_D.item(), loss_G.item())
)
batches_done = epoch * len(dataloader) + i
if batches_done % opt.sample_interval == 0:
# Save image grid with upsampled inputs and SRGAN outputs
imgs_lr = nn.functional.interpolate(imgs_lr, scale_factor=4)
gen_hr = make_grid(gen_hr, nrow=1, normalize=True)
imgs_lr = make_grid(imgs_lr, nrow=1, normalize=True)
img_grid = torch.cat((imgs_lr, gen_hr), -1)
save_image(img_grid, "images/%d.png" % batches_done, normalize=False)
if opt.checkpoint_interval != -1 and epoch % opt.checkpoint_interval == 0:
# Save model checkpoints
torch.save(generator.state_dict(), "saved_models/generator_%d.pth" % epoch)
torch.save(discriminator.state_dict(), "saved_models/discriminator_%d.pth" % epoch)
반응형
'컴퓨터비전(CV) > 논문 구현' 카테고리의 다른 글
| [논문 구현]Fully Convolutional Networks for Semantic Segmentation(FCN) (0) | 2022.03.16 |
|---|
댓글