[논문 리뷰]Fully Convolutional Networks for Semantic Segmentation(FCN, Segmentation 분야)
Fully Convolutional Networks for Semantic Segmentation(FCN)
https://arxiv.org/abs/1411.4038
Fully Convolutional Networks for Semantic Segmentation
Convolutional networks are powerful visual models that yield hierarchies of features. We show that convolutional networks by themselves, trained end-to-end, pixels-to-pixels, exceed the state-of-the-art in semantic segmentation. Our key insight is to build
arxiv.org
Segmentation이란?
Segmentation(분할) 분야는 컴퓨터비전 분야 중 가장 많이 다뤄지는 분야로
Image classification(이미지 분류) : 입력된 이미지가 어떤 label에 해당하는지 분류하는 작업
Detection (발견) : 입력된 이미지 안에 어떠한 물체가 있는지 탐지한다.
Segmentation (분할) : 입력된 이미지 안에 어떠한 물체가 있는지 '픽셀' 단위로 탐지한다.

Fully Convolutional Networks for Semantic Segmentation의 논문은 2014년 발행되었다.
기존 Image classification 모델들은 출력층이 FC layer(fully-connected)로 이루어져 있다.
이때 FC layer를 사용함으로써 갖는 문제점이 있는데,
1. feature의 위치정보가 사라진다.
-> segmentation 분야에서는 이미지에 있는 객체에 해당하는 픽셀마다의 레이블을 설정하는 것이 중요한데, 차원을 줄이기 위해 사용하는 fc layer를 통과한 후에 위치정보가 사라지는 것은 큰 문제 중 하나이다.
(모든 노드들이 곱해져서 더해지기 때문)
2. input image의 크기가 고정된다.
논문 초록에서 보면
We adapt contemporary classification networks (AlexNet, the VGG net , and GoogLeNet) into fully convolutional networks and transfer their learned representations by fine-tuning to the segmentation task
(FCN 논문 인용)
와 같이 Image classification에서 사용하는 모델들인 AlexNet, VGG, GoogleNet들을 transfer learning과 pine tuning을 사용하여 Segmentation 처리를 할 수 있도록 한다고 말한다.
논문에서는 VGG-16를 채택하였고, GoogleNet에 대해서는 마지막의 loss layer만 사용하기 위해 마지막의 classification을 위한 classifier layer(FC layers) 대신, 1*1 convolution으로 변경하였다고 한다.
-> 입력값을 받아서 위치정보를 가지는 heat map 생성
이후 PASCAL class에 대한 21개의 label에 대해 점수를 예측할 수 있도록 하였다.
classification 에서 segmentation 분야로 Fine-tuning 하는 것은 성능이 그당시 모델과 비교해보았을 때 성능(SOTA)가 획기적으로 상승할 수 있다는 것을 보여주었다고 한다.(VGG-16 모델에만 해당하고, 실험 결과 GoogLeNet은 segmentation 분야에서 dismatch한 결과를 보여주었다고 한다.)
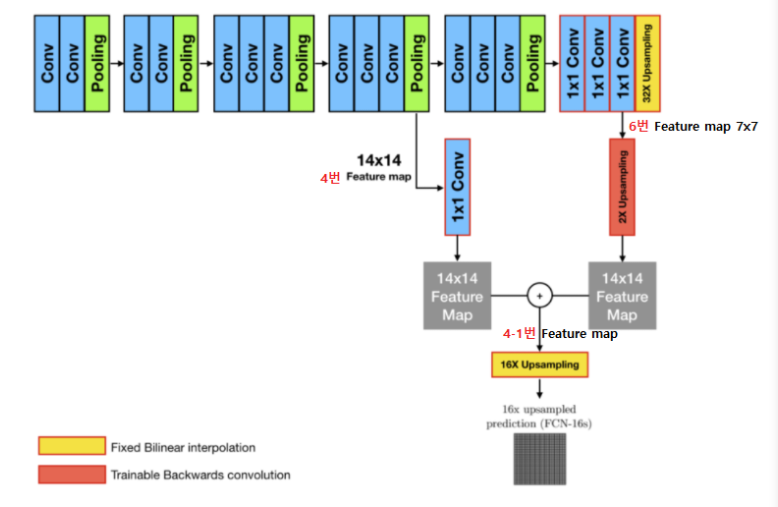
FCN 모델 흐름도


1. pool4 layer에서 1x1 conv layer를 추가하여
class에 대한 예측값을 만들어 냄
2. conv7 layer에서 선형 보간법(bilinear interpolation)을 이용하여 2x upsampling(Transposed Convolution)을 뒤에 추가하고, 이와 위에서 만들어낸 pool4 prediction을 더한다.
->VGG-16 모델의 input size는 224*224이므로 pool5 layer를 거치게 되면 7*7까지 축소한다. pooling 과정에서 특징의 손실이 일어나게 되는데 이를 보완하기 위해 모델 중간 과정에서의 feature map을 fuse하여 특징을 살리려는 것이 목표이다.
이때 learning rate는 100의 약수의 형태로 감소한다.


논문에 의하면 skip net을 사용함으로써 mean IU가 3.0에서 62.4로 획기적으로 증가함을 보여주었다.
FCN 논문에서 훈련 optimization 방법으로는 모멘텀(=0.9)을 이용한 SGD를 이용하였고, learning rates는 0.0001,0.00001,0.000001을 사용하였다고 한다.
