[논문 리뷰] ELECTRA: PRE-TRAINING TEXT ENCODERS AS DISCRIMINATORS RATHER THAN GENERATORS, 2020
https://arxiv.org/pdf/2003.10555.pdf
Abstract
BERT와 같은 MLM pre-training methods는 input을 [MASK]와 같은 token으로 바꾸고,
해당 token들을 original token으로 복원시키려는 방식으로 훈련된다.
이러한 방법은 좋은 성능을 내긴 하지만, 효과적인 성능을 위해서는 매우 많은 양의 컴퓨팅 자원이 필요하다.
저자는 'replaced token detection'이라는 sample-efficient pre-training task를 제안하였다.
input을 masking하는 것 보다는 조그마한 generator가 sampling한 plausible alternative samples들로 대체한다.
그리고 main model은 token이 generator가 만들어낸 것인지 아닌지 판별하는 discriminator로서 학습된다.
Introduce
현재 SOTA의 성능을 내고 있는 denoising autoencoder 학습 방법의 경우
input sequence 중 약 15% 정도만 선택하여 masking한다. 그리고 다시 original input으로 복원하도록 훈련이 진행되는데, 양방향 정보를 고려한다는 점에서 효과적인 성능이 나오게 되었지만, 하나의 예시마다 15%정도만 학습이 진행되기 때문에 좋은 성능을 내기 위해서는 cost가 많이 든다는 것이 문제점으로 제기되었다.
저자는 'Replaced Token Detection'을 제안하여 generator가 만들어낸 token을 model이 진짜인지 아닌지 구별하는 방법으로 학습을 진행하도록 한다.
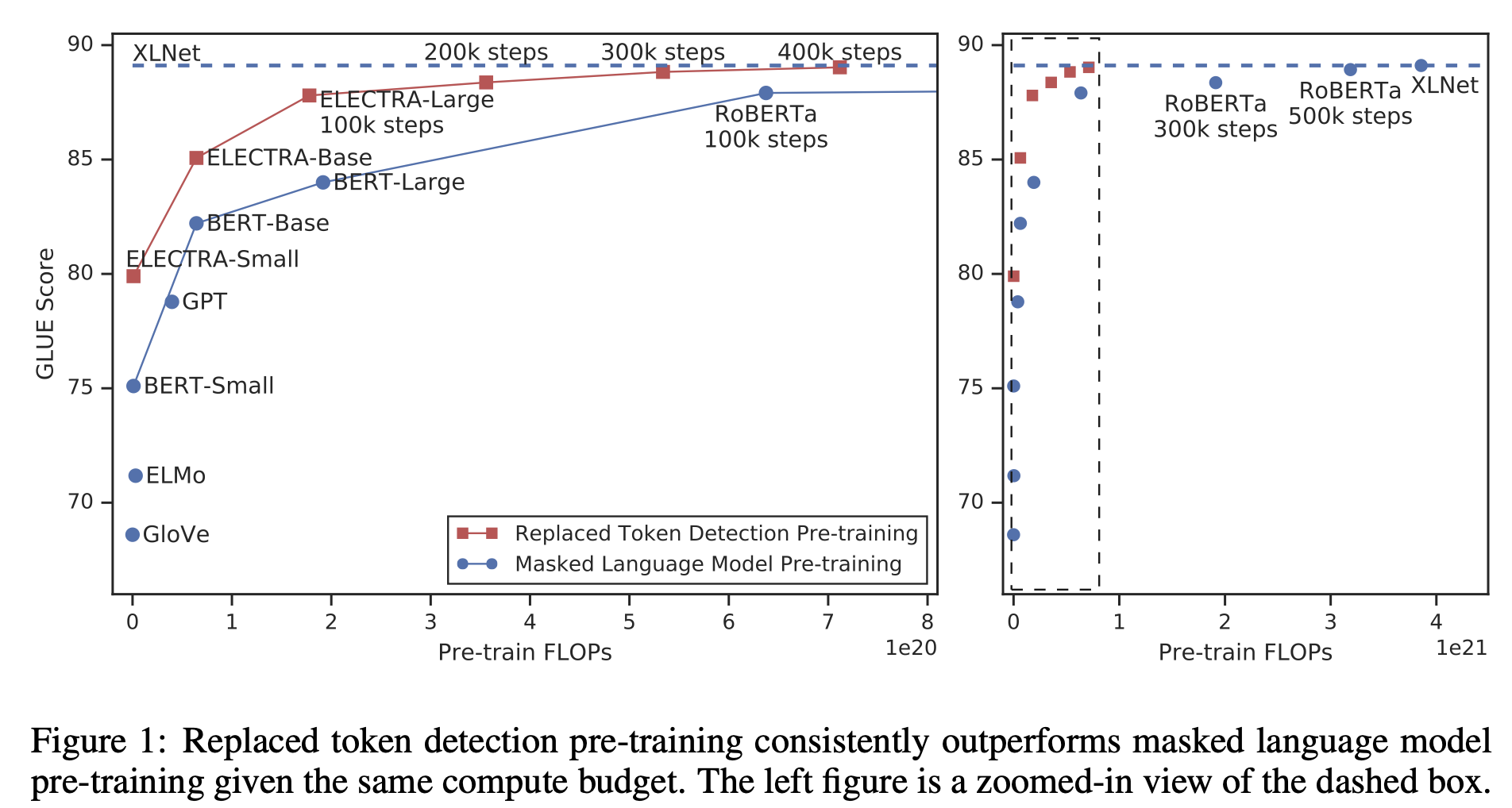
ELECTRA의 효율성에 대해 살펴보면
같은 모델 크기와 계산량일 때의 성능을 비교해 보았을 때, 모든 training 과정에서 다른 모델보다 높은 성능을 보이는 것을 확인할 수 있다.
또한 ELECTRA-Small의 경우 single GPU로 4일이면 학습이 완료된다고 하였는데, 해당 모델의 parameter는 BERT-Large의 1/20, 계산량은 1/135 정도입니다. 또한 BERT-small 보다 GLUE score가 5 points나 높고, BERT-LARGE보다 좋은 성능을 낸다고 한다.
이는 ELECTRA-Large의 경우도 마찬가지인데, RoBERTa나 XLNet보다 1/4의 계산량, 더 적은 파라미터로 학습을 진행하였을 때에도 해당 모델들과 비슷한 성능을 보였다고 말합니다.
Method

Generator는 token에 대한 output distribution을 만들어 내는 model이지만 여기서는 주로 small language model로서 사용된다.
해당 모델은 GAN과 같이 동작하지만 여기서는 generator만 학습하고, GAN method에서처럼 adversarially하게 학습을 진행하지는 않는다고 한다.(text에서 GAN을 적용하기는 힘듦)
pre-training 이후에는 generator는 버리고, fine-tune된 discriminator만 사용하여 task를 수행한다고 한다.
이 논문에서는 Generator G와 Discriminator D 두개의 neural network를 훈련한다.
각각의 network는 input token sequence x = [x1,...,xn] 를 contextualized vector representation h(x)=[h1,...,hn]으로 mapping하는 encoder로 구성되어있다.
주어진 위치 t에서, generator는 확률값을 output으로 하게 되는데, 특정 token xt를 만들어 낼 확률값을 의미한다.

e : token embedding
위치 t에서 discriminator는 xt가 'real'인지 아닌지 예측한다.

Generator는 MLM을 수행하기 위해 training 한다.
input x=[x1,x2,..,xn]이 주어진 경우, MLM은 처음에 마스킹할 random set of position을 선택한다. m = [m1,...,mk]
그리고 선택된 위치를 [MASK] token 으로 바꾼다. x^masked = REPLACE(x,m,[MASK])
Generator는 이 경우 masked-out token의 original identities를 예측하도록 학습한다.
Discriminator는 해당 token이 generator가 만들어낸 token인지 아닌지 구별할 수 있도록 훈련을 진행한다.
또한, corrupted example x^corrupt를 만들어내 masked-out token을 generator sample로 대체하고, discriminator가 x^corrupt가 original input x와 같은지 다른지를 판단한다.

Loss function은 다음과 같다.

이 논문에서는 GAN의 아이디어를 차용하였지만, 몇가지 다른점이 있다.
1) Generator가 original과 동일한 token을 생성하게 되었을 때, GAN에서는 이를 fake라고 판단하지만, ELECTRA에서는 positive sample이라고 판단한다.
2) GAN과는 달리 Adversarially하게 학습하지 않고, Generator만 학습을 진행한다.
generator에서 sampling하는 과정에서 back-propagation이 불가능하기 때문이고, reinforcement learning으로 이를 구현하여 학습을 진행해보았지만 오히려 성능이 안좋아지는 결과를 내었다고 한다.
3) GAN에서는 input으로 noise를 사용하였지만, ELECTRA에서는 그렇지 않았다는 점
마지막으로 대용량 코퍼스 X에 대해서 아래와 같은 loss를 최소화 하도록 학습한다.

discriminator는 generator로 back-propagation 되지 않기 때문에, 모든 pre-training이 끝난 후에는 generator를 버리고 discriminator로만 fine-tuning을 진행하여 task를 처리하게 됩니다.
Conclusion
이 논문에서는 Language Representation Learning을 위한 Replaced Token Detection을 제안한다.
MLM에 비해 훨씬 효율적이고, 성능이 더 뛰어남을 확인할 수 있었다. 특히 다른 모델들에 비해 계산량이 훨씬 적은 경우에도 동등하거나 그 이상의 성능을 내는 것을 실험을 통해 확인할 수 있었다.